News
Tenured!

Jiabei Zhu wins Best Student Paper Award in Optica Imaging Congress
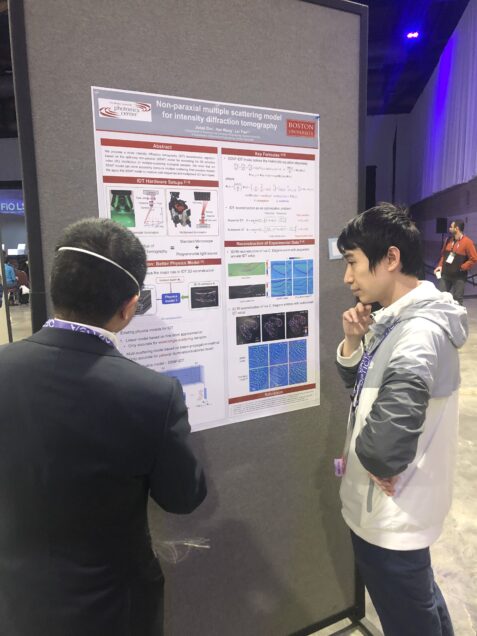
Congratulations to Jiabei Zhu for winning the Best Student Paper Award in Optica Imaging Congress 3D Conference, for his paper on “3D Phase Imaging from Intensity Measurements with Non-Paraxial Multiple Scattering Model”.

Hao Wang wins Best Student Paper Award in Optica Imaging Congress
Congratulations to Hao Wang for winning the Best Student Paper Award in Optica Imaging Congress Digital Holography Conference, for his paper on "wide-field, high-resolution reflection-mode Fourier ptychographic microscopy".

CISL at Optica Imaging Congress 2023

Hao Wang
Wide-field, high-resolution reflection-mode Fourier ptychographic microscopy
* best student paper award 1st place

Jiabei Zhu
3D Phase Imaging from Intensity Measurements with Non-Paraxial Multiple Scattering Model
* best student paper award 1st place
* featured in Optica news.

Qianwan Yang
Advancing Computational Miniature Mesoscope With Simulator-Based Deep Learning Reconstruction
* featured in Optica news.

Guorong Hu
Caustic Illumination-based HiLo Microscopy

Lei Tian
Computational 3D Phase Imaging by Intensity Diffraction Tomography * invited

Lei Tian
Computational Miniature Mesoscope: augmenting miniature optics with algorithms for large-scale 3D fluorescence imaging * invited
Excited to attend CZI Imaging 2023 Annual Meeting
Full CZI Imaging program group

Scialog Fellows

Shiyi defended PhD!

Congratulations, Dr. Cheng!
=============================
Title: Augmenting Label-free Imaging Modalities with Deep Learning based Digital Staining
Presenter: Shiyi Cheng
Date: Monday, July 10th, 2023
Time: 11:00 am to 1:00 pm
Location: 8 Saint Mary's Street, Room 339
Advisor: Professor Lei Tian
Chair: Professor Ari Trachtenberg
Committee: Professor Lei Tian, Professor Eshed Ohn-Bar, Professor David A. Boas, Professor Irving Bigio, Professor Ji-Xin Cheng.
Abstract:
Label-free imaging techniques provide valuable insights into biological samples and processes in their native states, eliminating the need for labor-intensive and potentially disruptive processes of physical staining. However, these methods often lack structural and molecular specific information. To overcome this limitation, recent advances in deep learning based digital staining techniques have shown the ability to virtually introduce digital labels or stains into label-free images, which enables extracting rich information that would typically require physical staining. The integration of label-free imaging and digital staining holds great potential for significantly expanding the toolkit for biomedical imaging, facilitating improved analysis, and enhancing our understanding of biomedical sciences at both the cellular and tissue level. In this thesis, I explore supervised and semi-supervised methodologies for digital staining and their applications in augmenting label-free imaging, with a focus on imaging cytometry and human brain imaging.
In the first part of the thesis, I present a novel integration of multi-contrast dark-field reflectance microscopy and digital staining by supervised deep learning. This method enables multiplexed immunofluorescence labeling of subcellular features and single cell cytometry. By leveraging the rich structural information and sensitivity of reflectance microscopy, the digital staining method accurately predicts subcellular features and achieves up to 3 times improvement in prediction accuracy over the state-of-the-art techniques. Additionally, the method accurately reproduces single-cell level structural phenotypes related to cell cycles. The multiplexed digital labeling enables multi-parametric single-cell profiling across a large cell population.
In the second part, I developed a novel semi-supervised digital staining technique for serial sectioning OCT (S-OCT) for 3D histological imaging of human brain tissue. The deep learning model integrates unpaired image translation, a biophysical model, and unsupervised cross-modality image registration. The digital staining model enables the translation of S-OCT images to Gallyas silver staining, provides consistent staining quality across different samples, and enhances contrast across cortical layer boundaries, enabling reliable layer differentiation. Importantly, the integration of S-OCT and digital staining allows volumetric histological imaging while preserving complex 3D geometry on centimeter-scale brain tissue blocks. In addition, our pilot study demonstrates promising results on other anatomical regions acquired from different S-OCT systems.
In summary, I investigated deep-learning-based digital staining techniques for augmenting two types of label-free imaging modalities. I showcased two important applications in the field of single-cell immunofluorescence microscopy and mesoscale 3D histological human brain imaging. I expect two major potential impacts from my thesis work. First, the integration of digital staining techniques with multi-contrast microscopy can potentially enhance the throughput of single-cell imaging cytometry and phenotyping. Second, the integration of digital staining techniques with S-OCT can potentially enable high-throughput human brain imaging, facilitating comprehensive studies on the brain's structure and function. Through this exploration, this thesis advances the digital staining technique and its applications for various biomedical disciplines.
Lei is selected as a Fellow of Scialog: Advancing BioImaging


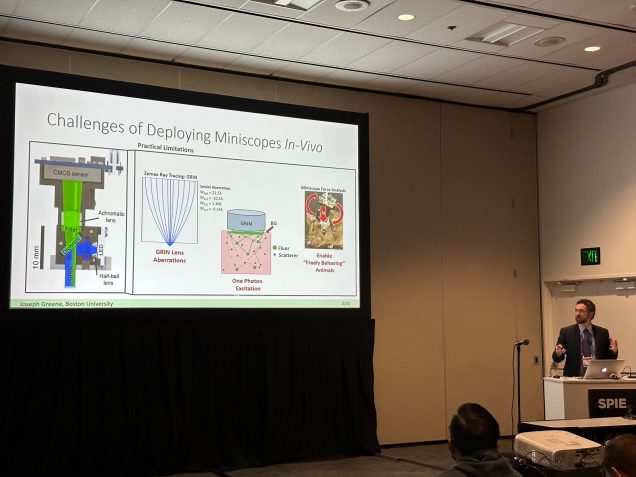
Joe, Chang present at SPIE Photonics West


Qianwan Yang wins Emil Wolf Outstanding Student Paper Award
Qianwan Yang wins Emil Wolf Outstanding Student Paper Award in Optica Frontier in Optics Congress for her work on "Computational Miniature Mesoscope with deep learning reconstruction". Congratulations!
Joe, Qianwan, Jiabei, Hao present at Optica FiO conference

J. Zhu*, H. Wang*, L. Tian, “Non-paraxial multiple scattering model for intensity diffraction tomography”, Optica Frontier in Optics, Oct. 2022.
J. Greene*, Y. Xue*, J. Alido*, A. Matlock*, G. Hu*, K. Kilic, I. Davison, L. Tian, “Pupil engineering in miniscopes for extended depth-of-field neural imaging”, Optica Frontier in Optics, Oct. 2022.
Q. Yang*, Y. Xue*, G. Hu*, L. Tian, “Computational Miniature Mesoscope with deep learning reconstruction”, Optica Frontier in Optics, Oct. 2022. * Emil Wolf Outstanding Student Paper Award
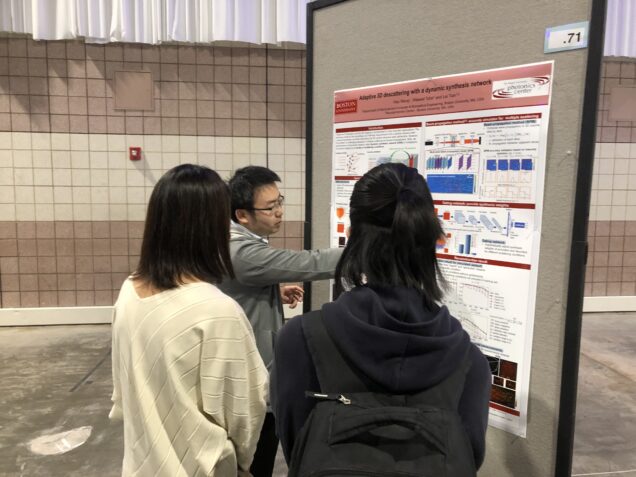
H. Wang*, W. Tahir*, L. Tian, “Adaptive volumetric descattering in digital holography”, Optica Frontier in Optics, Oct. 2022.