The GODIVA Model of Speech Sound Sequencing
In collaboration with Daniel Bullock and Jason Bohland, we have developed a neural network model of the brain computations underlying the sequencing and initiation of speech sounds called Gradient Order DIVA (GODIVA). The mechanisms described by the model lie at the intersection between the language and motor control networks for speech. A schematic of the model is illustrated below, and Matlab/Simulink code implementing a simplified version of the model is available on our Software page.
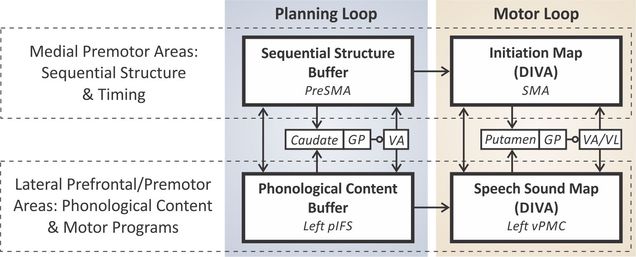
Schematic of the GODIVA model (adapted from Guenther, 2016, Chapter 8).
Publications
- Guenther, F.H. (2016). Neural Control of Speech. Cambridge, MA: MIT Press.
- Civier, O., Bullock, D., Max, L., and Guenther, F.H. (2013). Computational modeling of stuttering caused by impairments in a basal ganglia thalamo-cortical circuit involved in syllable selection and initiation. Brain and Language, 126, pp.263-278. PMCID: PMC3775364
- Bohland, J.W., Bullock, D. and Guenther, F.H. (2010). Neural Representations and Mechanisms for the Performance of Simple Speech Sequences. Journal of Cognitive Neuroscience, 22 (7), pp. 1504-1529. PMCID:PMC2937837