The DIVA Model of Speech Motor Control
DIVA (Directions Into Velocities of Articulators) is a neural network model of speech motor skill acquisition and speech production. In computer simulations, the model learns to control the movements of a computer-simulated vocal tract in order to produce speech sounds. The model’s neural mappings are tuned during a babbling phase in which auditory feedback from self-generated speech sounds is used to learn the relationship between motor actions and their acoustic and somatosensory consequences. After learning, the model can produce arbitrary combinations of speech sounds, even in the presence of constraints on the articulators.
A schematic of the model is provided below, and Matlab/Simulink code implementing the model is available on our Software page. Each block in the diagram corresponds to a hypothesized map of neurons in a particular region of the brain. DIVA provides unified explanations for a number of long-studied speech production phenomena including motor equivalence, contextual variability, speaking rate effects, anticipatory coarticulation, and carryover coarticulation. Because the model’s components are localized to particular stereotactic coordinates in the brain, it is capable of accounting for a wide range of neuroimaging studies of speech production.
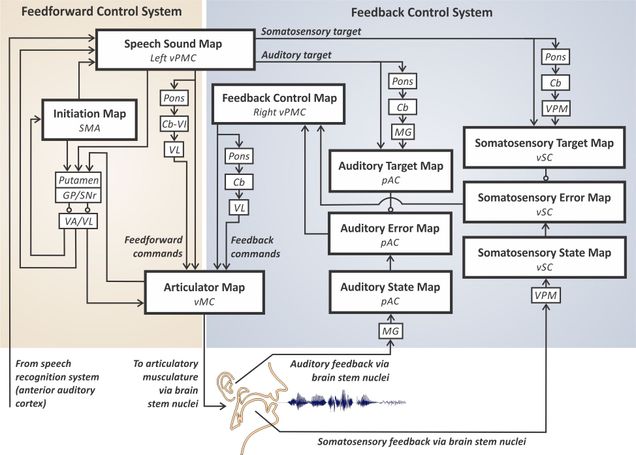
Schematic of the DIVA model (Guenther, 2016, Chapter 3).
Publications
- Guenther, F.H. (2016). Neural Control of Speech. Cambridge, MA: MIT Press.
- Guenther, F.H. and Vladusich, T. (2012). A neural theory of speech acquisition and production. Journal of Neurolinguistics. 25, pp. 408-422. PMCID: PMC3375605
- Tourville, J.A. and Guenther, F.H. (2011). The DIVA model: A neural theory of speech acquisition and production. Language and Cognitive Processes, 25, pp. 952-981. PMCID:PMC3650855
- Golfinopoulos E., Tourville J.A., Guenther F.H. (2010). The integration of large-scale neural network modeling and functional brain imaging in speech motor control. NeuroImage 52, pp. 862-874. PMCID:PMC2891349
- Guenther, F.H. (2006) Cortical interactions underlying the production of speech sounds. Journal of Communication Disorders, 39, pp. 350-365. PMID:16887139
- Guenther, F.H., Ghosh, S.S., and Tourville, J.A. (2006) Neural modeling and imaging of the cortical interactions underlying syllable production. Brain and Language, 96(3), pp. 280-301. PMCID:PMC1473986
- Nieto-Castanon, A., Guenther, F.H., Perkell, J.S., Curtin, H.D. (2005) A modeling investigation of articulatory variability and acoustic stability during American English /r/ production. Journal of the Acoustical Society of America, 117(5), pp. 3196-3212. PMID:15957787
- Guenther, F.H., Ghosh, S.S., and Nieto-Castanon, A. (2003) A neural model of speech production. Proceedings of the 6th International Seminar on Speech Production, Sydney, Australia.
- Guenther, F.H. (2001) Neural modeling of speech production. Proceedings of the 4th International Nijmegen Speech Motor Conference, Nijmegen, The Netherlands.
- Guenther, F.H., Hampson, M., and Johnson, D. (1998) A theoretical investigation of reference frames for the planning of speech movements. Psychological Review, 105, pp. 611-633. PMID:9830375
- Guenther, F.H. (1995). Speech sound acquisition, coarticulation, and rate effects in a neural network model of speech production. Psychological Review, 102, pp. 594-621. PMID:7624456
- Guenther, F.H. (1995) A modeling framework for speech motor development and kinematic articulator control. Proceedings of the XIIIth International Congress of Phonetic Sciences (vol. 2, pp. 92-99). Stockholm, Sweden:. KTH and Stockholm University.
- Guenther, F.H. (1994) A neural network model of speech acquisition and motor equivalent speech production. Biological Cybernetics, 72, pp. 43-53. PMID:7880914