News

[I wrote this a few years ago, but it is still relevant, perhaps even more so now -PD]
I’ve been a privacy advocate for a long time; back in the mid-90s I’d wear my PGP ‘munition’ T-shirt while walking around the Boston common, both to support Phil Zimmerman’s defense fund and to enact my own small protest against government restrictions on free speech.
I’m also a big fan of Cory Doctorow’s writing, and a few months read both Little Brother and Homeland, his vision of not-too-distant future of a dystopian United States in which Homeland Security mounts an all-out offensive against freedom in the name of safety. The books are frightening in that it’s easy to see a path between where we are right now and the world he depicts. I stocked up on tin foil after finishing the books.
I resolved to do my part to help secure the basic human right of freedom of speech, even if in just a small way, by setting up a Tor relay on one of my servers. I run a small business and have ample bandwidth and compute cycles, and I felt that helping the Tor network grow was a great way to participate in the free-speech movement.
The Tor network architecture uses a three-hop graph. A user connects to the network via a bridge; the next hop is to a relay, and the final hop to an exit node which makes the final hop to the service the user wants to use. Bridges and relay nodes are equivalent in terms of how they are set up, and a bridge can be either public or hidden, the latter being used to help obscure the initial connection tor the Tor network in regimes where network traffic is heavily scrutinized or suppressed. You can read full details of the architecture at the Tor Project home page.
Exit nodes carry potential legal issues and so I decided to run a relay. It takes only a few minutes to set this up on a Linux distribution…a download and a few configuration file tweaks and you are up and running. I gave the node 1 MB/s of bandwidth so that it would have a good chance of being promoted to being a published entry point.
I set the node up on a Monday. The first sign of trouble was on Wednesday, when my wife asked why she couldn’t watch a show on Hulu. I took a look and saw an ominous message: “Based on your IP-address, we noticed that you are trying to access Hulu through an anonymous proxy tool…” The streaming ABC site displayed a similar message. The new Tor relay was an obvious source of the message, but I’d also recently been using a VPN to watch World Cup games that were blocked in the USA, and that could’ve been a trigger, too.
The next day I logged on to one of my banking sites. I was blocked. A second banking site had also blocked me. I needed to renew a domain at Network Solutions. Denied: “There’s something wrong with your credit card…”
What had happened?
A fundamental weakness of Tor is that in order to connect to the first node, you need to know the IP address of the first node. Tor handles this in two ways; a small set of bridge nodes are kept secret and distributed only by email…these are used by dissidents in China, for example, where Tor traffic is heavily censored. The large majority of bridges, though, are available in public lists, and many companies scrape these lists and blacklist any IP found on them. I’d been blacklisted for supporting free speech.
Some of the blocks were easy to fix. I called Hulu and the support technician manually removed my IP from their blacklist. Others (my banks, for example) cleared themselves automatically a few days after I disabled my Tor relay.
Some were not so easy to fix. Network Solutions is still blocking me, and just yesterday I tried to do an online transaction on my state government’s web site: “There is something wrong with your credit card…”
My solution to this nagging problem is the same one that I used to watch the blocked World Cup games…a VPN to a server somewhere else in the world. Since my IP is blacklisted, I just come in with a different IP.
My advice to anyone who wants to support free speech by running a Tor relay on their home or small business network is simple:
Don’t do it.
The Tor Project downplays or ignores the risk of running a Tor relay, focusing instead on exit nodes. Their goal is to grow the network, so I can’t fault them. However, it’s clear that many organizations are throwing a wide net around Tor traffic and putting all of it in the ‘evil-doer’ basket. Even if you are just trying to do your part as a citizen of the world to promote free speech, you will be slapped down. My IP presumably is now on watch lists that I don’t know about, both private and governmental. Is my traffic being collected? What tripwires did this trigger? What other ramifications are there? These are questions that I don’t know the answer to right now.
I still support Tor and what it stands for. The Tor Project is making a big push right now to encourage individuals to create Tor nodes in the Amazon cloud, and I’m all for that as long as you keep in mind that Amazon is a third party and subject to subpoena and to national security orders. It might well be that the AWS Tor nodes are currently under heavy scrutiny…we just don’t know. If you don’t physically own the entry node, there’s no guarantee that your traffic is not being de-anonymized. The Tor Browser Bundle can be useful in providing a layer of anonymity to your web browsing, but you should approach it with a dose of skepticism.
If your goal is anonymous network access, one approach would be to set up a private Tor entry point, one that you physically control, and obfuscate the traffic coming out of it. This would prevent your IP from being scraped off the list of public relays, and presumably would help prevent traffic analysis at your ISP from identifying your IP as being part of the Tor network. This approach doesn’t help the Tor project, really, but it will help anonymize your traffic. The Tor Project maintains a list of hidden entry nodes, but it’s trivial to build a list of them (they are distributed by email) and so you should assume that they have been compromised and just use your private bridge.
I still want to promote free speech. My focus is shifted away from Tor and I’m instead promoting the ‘encrypt everything’ movement. The idea is that if more people use encryption for everyday communication such as email and IM messages, the encrypted traffic becomes the norm rather than sticking out like a big flag. Unfortunately, 20 years after Zimmerman posted his PGP code, it’s still not easy for the average user to implement strong encryption. That’s where I’ll spend my effort…in making things simpler.
Applications built using the MEAN stack typically use Node, MongoDB and Express on the back end to implement business logic fronted by a RESTful interface. Most of the work is done on the back end, and Angular serves as an enhanced view in the MVC (model-view-controller) pattern. Keeping business rules and logic on the back end means that the application is view-agnostic; switching from Angular to React or straight jQuery or PHP should result in the same functionality.
It's often the case that we need to protect some back-end routes, making them available only to authenticated users. The challenge is that our back-end services should be stateless, which means that we need a way for front-end code to provide proof of authentication at each request. At the same time, we can't trust any front-end code, since it is out of our control. We need an irrefutable mechanism for proving authentication that is entirely managed on the back end. We also want the mechanism to be out of the control of the client code, and done in such a way that it would be difficult or impossible to spoof.
JSON Web Tokens (JWTs) are a good solution for these requirements. The token is basically a JavaScript object in three parts:
JWTs are formally described in RFC7519. There's nothing inherently authentication-y about them -- they are a mechanism to encapsulate and transmit data between two parties that ensures the integrity of the information. We can leverage this to give clients a way to prove their status without involving the client at all. Here's the flow:
Using a cookie to transmit the JWT provides a simple, automated way to pass the token back and forth between the client and the server and also gives the server control over the lifecycle of the cookie. Marking the cookie httpOnly means that it is unavailable to client functions. And, since the token is signed using a secret known only to the server, it is difficult or impossible to spoof the claims in the token.
The implementation discussed in this article uses a simple hash-based signing method. The header and body of the JWT are Base64 encoded, and then the encoded header and body, along with a server-side secret, are hashed to produce a signature. Another option is to use a public/private key pair to sign and verify the JWT. In the example, the JWT is handled only on the server, and so there's no benefit to using a signing key.
Let's take a look at some code that implements our workflow. The application that I'm using in the following examples relies on third-party OAuth authentication from Twitter, and minimal profile information is held over for a user from session to session. The Twitter access token returned after a successful authentication is used as a key to a user record in a mongoDB database. The token exists until the user logs out or the user re-authenticates after having closed the browser window (thus invalidating the session cookie containing the JWT). Note that I've simplified error handling for readability.
Two convenience packages are used in the following code examples:
I also use Mongoose as a layer on top of mongoDB; it provides ODM via schemas and also several handy query methods.
Once authentication with Twitter completes, Twitter invokes a callback method on the application, passing back an access token and secret, and information about the user such as their Twitter ID and screen name (passed in the results object). Relevant information about the user is stored in a database document:
User.findOneAndUpdate( {twitterID: twitterID},
{
twitterID: twitterID,
name: results.screen_name,
username: results.screen_name,
twitterAccessToken: oauth_access_token,
twitterAccessTokenSecret: oauth_access_token_secret
},
{'upsert': 'true'},
function (err, result) {
if (err) {
console.log(err)
}
else {
console.log("Updated", results.screen_name, "in database.")
}
})
The upsert option directs mongoDB to create a document if it not present, otherwise it updates an existing document.
Next, a JWT is assembled. The jsonwebtoken package takes care of creating the header of the JWT, so we just fill in the body with the Twitter access token. It is the access token that we'll use to find the user in the database during authorization checks.
const jwtPayload = {
twitterAccessToken: oauth_access_token
}
The JWT is then signed.
const authJwtToken = jwt.sign(jwtPayload, jwtConfig.jwtSecret)
jwtSecret is a string, and can be either a single value used for all users (as it is in this application) or a per-user value, in which case it must be stored along with the user record. A strategy for per-user secrets might be to use the OAuth access token secret returned by Twitter, although it introduces a small risk if the response from Twitter has been intercepted. A concatenation of the Twitter secret and a server secret would be a good option. The secret is used during validation of the signature when authorizing a client's request. Since it is stored on the server and never shared with the client, it is an effective way to verify that a token presented by a client was in fact signed by the server.
The signed JWT is placed on a cookie. The cookie is marked httpOnly, which restricts visibility on the client, and its expiration time is set to zero, making it a session-only cookie.
const cookieOptions = {
httpOnly: true,
expires: 0
}
res.cookie('twitterAccessJwt', authJwtToken, cookieOptions)
Keep in mind that the cookie isn't visible to client-side code, so if you need a way to tell the client that the user is authenticated you'll want to add a flag to another, visible, cookie or otherwise pass data indicating authorization status back to the client.
We certainly could send the JWT back to the client as an ordinary object, and use the data it contains to drive client-side code. The payload is not encrypted, just Base64 encoded, and would thus be accessible to the client. It could be placed on the session for transport to and from the server, though this would have to be done on each request-response pair, on both the sever and the client, since this kind of session variable is not automatically passed back and forth.
Cookies, on the other hand, are automatically sent with each request and each response without any additional action. As long as the cookie hasn't expired or been deleted it will accompany each request back to the server. Further, marking the cookie httpOnly hides it from client-side code, reducing the opportunity for it to be tampered with. This particular cookie is only used for authorization, so there's no need for the client to see it or interact with it.
At this point we've handed the client an authorization token that has been signed by the server. Each time the client makes a request to the back-end API, the token is passed inside a session cookie. Remember, the server is stateless, and so we need to verify the authenticity of the token on each request. There are two steps in the process:
Simply checking the signature isn't enough -- that just tells us that the information in the token hasn't been tampered with since it left the server, not that the owner is who they say they are; an attacker might have stolen the cookie or otherwise intercepted it. The second step give us some assurance that the user is valid; the database entry was created inside a Twitter OAuth callback, which means that the user had just authenticated with Twitter. The token itself is in a session cookie, meaning that it is not persisted on the client side (it is held in memory, not on disk) and that has the httpOnly flag set, which limits its visibility on the client.
In Express, we can create a middleware function that validates protected requests. Not all requests need such protection; there might be parts of the application that are open to non-logged-in users. A restricted-access POST request on the URI /db looks like this:
// POST Create a new user (only available to logged-in users) // router.post('/db', checkAuthorization, function (req, res, next) { ... }
In this route, checkAuthorization is a function that validates the JWT sent by the client:
const checkAuthorization = function (req, res, next) { // 1. See if there is a token on the request...if not, reject immediately // const userJWT = req.cookies.twitterAccessJwt if (!userJWT) { res.send(401, 'Invalid or missing authorization token') }
//2. There's a token; see if it is a valid one and retrieve the payload // else { const userJWTPayload = jwt.verify(userJWT, jwtConfig.jwtSecret) if (!userJWTPayload) { //Kill the token since it is invalid // res.clearCookie('twitterAccessJwt') res.send(401, 'Invalid or missing authorization token') } else {
//3. There's a valid token...see if it is one we have in the db as a logged-in user // User.findOne({'twitterAccessToken': userJWTPayload.twitterAccessToken}) .then(function (user) { if (!user) { res.send(401, 'User not currently logged in') } else { console.log('Valid user:', user.name) next() } }) } } }
Assuming that the authorization cookie exists (Step 1), it is then checked for a valid signature using the secret stored on the server (Step 2). jwt.verify returns the JWT payload object if the signature is valid, or null if it is not. A missing or invalid cookie or JWT results in a 401 (Not Authorized) response to the client, and in the case of an invalid JWT the cookie itself is deleted.
If steps 1 and 2 are valid, we check the database to see if we have a record of the access token carried on the JWT, using the Twitter access token as the key. If a record is present it is a good indication that the client is authorized, and the call to next() at the end of Step 3 passes control to the next function in the middleware chain, which is in this case the rest of the POST route.
If the user explicitly logs out, a back-end route is called to do the work:
//This route logs the user out: //1. Delete the cookie //2. Delete the access key and secret from the user record in mongo // router.get('/logout', checkAuthorization, function (req, res, next) { const userJWT = req.cookies.twitterAccessJwt const userJWTPayload = jwt.verify(userJWT, jwtConfig.jwtSecret) res.clearCookie('twitterAccessJwt') User.findOneAndUpdate({twitterAccessToken: userJWTPayload.twitterAccessToken}, { twitterAccessToken: null, twitterAccessTokenSecret: null }, function (err, result) { if (err) { console.log(err) } else { console.log("Deleted access token for", result.name) } res.render('twitterAccount', {loggedIn: false}) }) })
We again check to see if the user is logged in, since we need the validated contents of the JWT in order to update the user's database record.
If the user simply closes the browser tab without logging out, the session cookie containing the JWT will be removed on the client. On next access the JWT will not validate in checkAuthorization and the user will be directed to the login page; successful login will update the access token and associated secret in the database.
In no particular order...
Some services set short expiration times on access tokens, and provide a method to exchange a 'refresh' token for a new access token. In that case an extra step would be necessary in order to update the token stored on the session cookie. Since access to third-party services are handled on the server, this would be transparent to the client.
This application only has one role: a logged-in user. For apps that require several roles, they should be stored in the database and retrieved on each request.
An architecture question comes up in relation to checkAuthorization. The question is, who should be responsible for handling an invalid user? In practical terms, should checkAuthorization return a boolean that can be used by each protecte route? Having checkAuthorization handle invalid cases centralizes this behavior, but at the expense of losing flexibility in the routes. I've leaned both way on this...an unauthorized user is unauthorized, period, and so it makes sense to handle that function in checkAuthorization; however, there might be a use case in which a route passes back a subset of data for unauthenticated users, or adds an extra bit of information for authorized users. For this particular example the centralized version works fine, but you'll want to evaluate the approach based on your won use cases.
The routes in this example simply render a Pug template that displays a user's Twitter accoun information, and a flag (loggedIn) is used to show and hide UI components. A more complex app will need a cleaner way of letting the client know the status of a user.
A gist with sampe code is availabe at gist:bdb91ed5f7d87c5f79a74d3b4d978d3d
One of the toughest things to get your head around in Javascript is how to handle nested asynchronous calls, especially when a function depends on the result of a preceding one. I see this quite a bit in my software engineering course where teams are required to synthesize new information from two distinct third-party data sources. The pattern is to look something up that returns a collection, and then look something else up for each of the members in the collection.
There are multiple approaches to this problem, but most rely on Javascript Promises, either from a third-party library in ES5 and earlier or ES6's built-in Promises. In this article we'll use both by using ES6 native Promises and the async.js package. This isn't a discussion of ES6 Promises per se, but it might help you get to the point of understanding them.
The file discussed here is intended to be mounted on a route in a Node/Express application:
//From app.js const rp = require('./routes/request-promises') app.use('/rp', rp)
[Unfortunately the WordPress implementation used here does a horrific job displaying code, so the code snippets below are images for the bulk of the discussion. The complete file is available at the bottom of the post.]
The route here uses two APIs:
https://weathers.co for current weather in 3 cities, and
https://api.github.com/search/repositories?q=<term> to search GitHub repos for the 'hottest' city.
In our example we'll grab weather for 3 cities, pick the hottest one, then hit GitHub with a search for repos that have that city's name. It's a bit contrived but we just want to demonstrate using the results of one API call to populate a second when all of them are asynch.
There are two packages (apart from Express) used:

The first is a reduced-size packaging of the standard request-promise package; we don't need all of the features of the larger library. request-promise itself is a wrapper that adds Promises to the standard request package used to make network calls, for example to an HTTP endpoint.
There's only one route in this module, a GET on the top-level URL. In the snippet above, this router is mounted at '/rp', and so the complete URL path is http://localhost:3000/rp (assuming the server is set to listen to port 3000).

On line 50 the async.waterfall method is used to create a chain of functions that will execute in turn. Each function returns a Promise, and so the next function in line waits until the preceding function's Promise is resolved. We need this because each function provides data that the following function will use in some way. That data is provided to each function in turn along with a callback, which is the next function in the waterfall.
async.waterfall takes two parameters in this implementation: An array of functions to call in order, and a final function (renderTable on line 51) to execute last. A small side note: The final function can be anonymous, but when debugging a big application it can be tough to figure out exactly which anonymous function out of potentially hundreds is causing a problem. Naming those functions helps immensely when debugging!
The first function in the waterfall, getCityTemperatures, calls the weathers.co API for each city in a hardcoded array. This is the first function in the waterfall and so it receives only one param, the callback (cb).

This is the most interesting function of the three because it has to do an API call for each city in the cities array, and they all are asynchronous calls. We can't return from the function until all of the city weather has been collected.
In each API call, once the current temperature is known it is plugged into the city's object in the cities array. (Note that weathers.co doesn't always return the actual current temperature. Often it is a cached value.) The technique here is to create a Promise that encompasses the API calls on line 83. This Promise represents the entire function, and it won't be resolved until all of the city weather has been collected.
A second Promise is set up in the local function getWeather on line 91, and that's the one that handles each individual city's API call. request.get() itself returns a Promise on line 92 (because
we are using the request-promise-lite package), and so we make the request.get() and follow it with a then() which will run when the API call returns. The resolve() at line 96 gets us out of this inner Promise and on to the next one.
Note that we don't yet execute getWeather(), we're just defining it here. Line 109 uses the Array.map method to return an array that has three functions in it. Each function has one of the city objects passed into it, and each returns a Promise (as defined on line 91). That cityPromises array looks like
[getWeather({name: 'Miami', temperature: null}), getWeather({name: 'Atlanta', temperature: null}), getWeather({name: 'Boston', temperature: null})]
after line 109 completes.
We still haven't executed anything. The mapping in line 109 sets us up to use the Promise.all( ) method from the ES6 native Promise library in line 121, which only resolves when all of the Promises in its input array have resolved. It's a bit like the async.waterfall( ) call from line 50, but in this case order doesn't matter. If any of the Promises reject, the entire Promise.all( ) structure rejects at that moment, even if there are outstanding unresolved Promises.
Once all of the Promises have resolved (meaning that each city's weather has been recorded, the then( ) in line 122 executes, and calls the passed-in callback with the now-complete array of cities and temperatures. The null value handed to the callback is interpreted as an error object.
Of interest here is that Promise.all( ) is, practically speaking, running the requests in parallel.
The next function in the chain, getHottestCity, simply finds the largest temperature in the array of cities and returns that city's object to the next function in the waterfall. This is synchronous code and so doesn't require a Promise.

Line 140 creates a slice with just the temperatures from the cities array and calls Math.max( ) to determine the largest value. Line 143 then looks for the hottest temperature in the original cities array and returns the corresponding object. Both of these lines use the ES6 way of defining functions with fat-arrow notation (=>), and line 140 uses the new spread operator.
Once the 'hot' city has been determined it is passed to the next function in the waterfall in line 148. Here again, the null is in the place of an error object.
The next-to-last function in the waterfall searches Github for projects that include the name of the 'hot' city discovered earlier. The User-Agent header in line 167 is required by the Github search API -- you can change it to any string that you like.
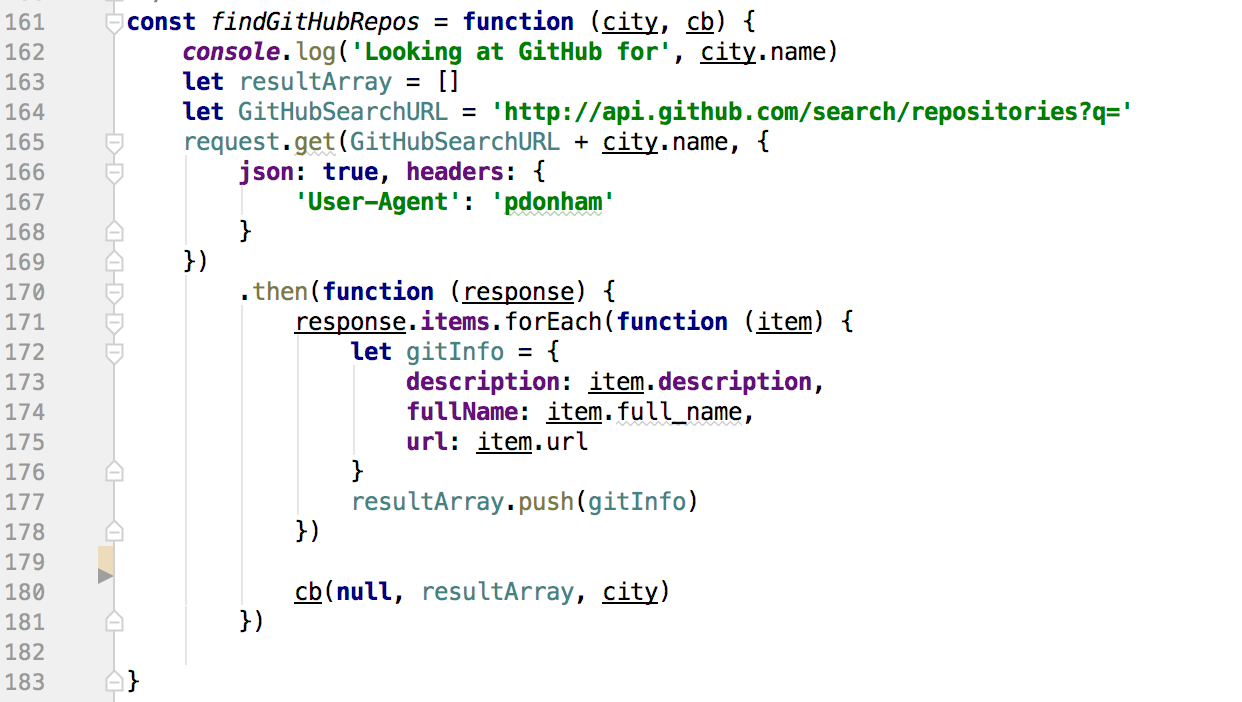
The API call in line 165 uses request-promise (from line 29) and so returns a Promise. Once the Promise is resolved, the then( ) function builds an array of objects from some of the data returned.
In line 180 the completed array of items is passed to the next function in the waterfall along with the original 'hot' city object.
The last function to execute simply takes the results of our waterfall and renders a Pug page on line 57.
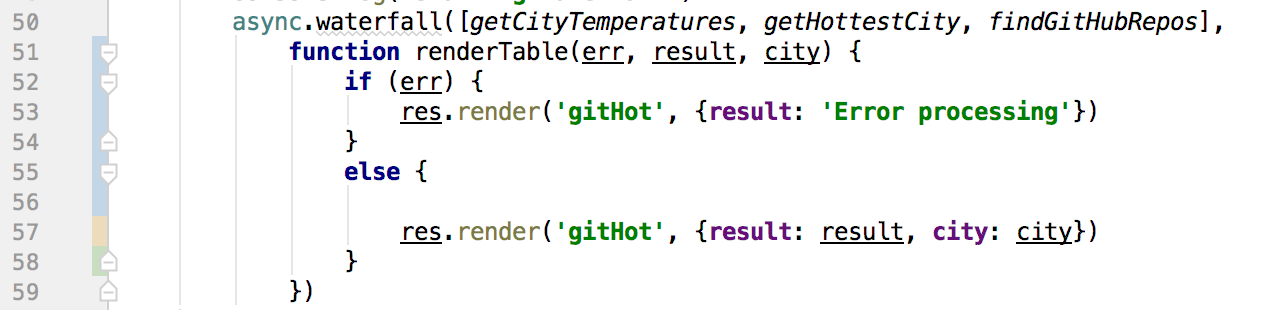
Here's a link to the complete file. If If you have questions or corrections, leave a comment!
The tl;dr: Assume that anything you do online is being recorded by the government.
I had a conversation this past week with one of my students who was interested in some of the operational aspects of anonymity; he wanted to know to what extent either Tor or a VPN or both would protect his identity against varying levels of potential adversaries, from coworkers to nation-states. I think that we here in the USA forget that in many parts of the world, speech, especially dissident speech, can be extremely dangerous.
A recurring theme of this conversation was the notion of trust. For example, when we talked about how VPNs work and how they might be used to secure communications like IM or email, it came down to the level of trust that you have in the VPN provider. What if that provider is logging everything that you do across the VPN? Is the VPN provider susceptible to a Five-Eyes warrant to turn over those logs, or being monitored covertly? How do you know that the VPN provider isn't really a government agency?
You don't.
On January 21st 2017, literally millions of people united in marches across the country protesting against an administration that they see as a threat to their freedoms. Those protests were organized and promoted on sites and services such as Twitter, Facebook, and Google without, I'm guessing, much thought about who else might be collecting and collating this information. We willingly expose enormous amounts of information about ourselves, our thoughts, and our actions on these sites every single day. Can we trust them?
We can't.
Edward Snowden showed us how deeply entrenched US intelligence agencies are in these sites, collecting, storing, and indexing nearly every message that flows through them. A body of secret law, interpreted by a court that meets in secret, ensures that these agencies can collect nearly anything that they ask for.
We have to assume that all of the email, texts, phone calls, and posts relating to today's protests have been collected.
Do we care? On some level I suppose we don't. We use these services, the Facebooks, the Twitters, the GMails, because they are convenient and efficient at reaching large numbers of people very quickly. For a large portion of our population, the 'internet' is Facebook. We post and tweet and like, not realizing that these posts and tweets and likes are used to create profiles of us, primarily for marketing purposes, but also for analysis by our government. I'm not saying that the NSA has a folder labeled 'Perry Donham' with all my posts and tweets collated in realtime, but I am saying that the data is there if an analyst wants to sort through it.
A photo from today's march in Washington really struck me: Japanese woman at Washington protest 21 January 2017. In it an elderly Japanese woman holds a sign that reads Locked Up by US Prez 1942-1946 Never Again! There are US citizens still alive who were put into detention camps by the US government during the second world war. George Takei, a US citizen who played Sulu on the iconic series Star Trek, was imprisoned by the US government from the age of five until the age of eight. The reason? He was of Japanese descent.
We are entering unknown political territory, with an administration guided by the far right that will wield enormous technical surveillance assets. We literally don't know what is going to happen next. It's time to think carefully about what we say and do, and who we associate with, online, in email, posts, tweets, texts, and phone calls. We know that this data is being collected now by our government. We don't know what the Trump administration will choose to do with it.
My advice is simply this: Every time you post or tweet or like, assume that it is being collected, analyzed, stored, and can be potentially used against you.
Worse, we've become dependent on 'the cloud' and how easy it is to store our information on services such as Dropbox, Google Docs, and Azure. Think about this. Do you know the management team at Dropbox? The developers? The people running the data Dropbox data center? Their network provider? You do not. The only reason that we trust Dropbox with our files is that 'they' said that 'they' could be trusted with them.
You might as well drive over to your local Greyhound terminal and hand an envelope with your personal files in it to a random person sitting on a bench. You know that person just as well as you do Dropbox.
I've been thinking a lot about trust and how false it is on the internet, and about how little we think about trust. In the next few posts I'll look at how the idea of trust has broken down and at how we can leverage personal trust in securing our communications and information.
A slight departure today from my usual computer science rants (er, posts) as I do a side-by-side sampling of two of my favorite bourbons.
First, let me say that I am a wheated bourbon fan, and my go-to pour is Old Weller Antique, which is a Buffalo Trace product and closely related to the Pappy van Winkle product line. When you can find it, OWA is a $25 bottle and is consistently delicious; I find it better tasting than Weller Special reserve which is usually a few dollars more. Sadly, over the past few years a myth has spread that the Weller line is a 'poor man's Pappy van Winkle' (especially if you blend the OWA and Special Reserve), and it's been difficult to find ever since. The rumor is that Old Weller is the also-ran barrels when it comes time to choose which will become Pappy van Winkle, which can sell for $500 per bottle or more. There's a shop in town that will sell you only one bottle of the limited supply that they get. SAD!
Old Rip van Winkle is a Buffalo Trace bourbon that uses their wheated mash bill; there's more wheat than rye in the recipe. Wheat tends to soften the flavor a bit...bourbons high in rye have a slightly astringent smell and taste, while the wheats are sweeter. In both recipes, of course, corn is the main ingredient, since that's what defines a bourbon. The parent company is Diageo. Old Rip is a ten-year-old bourbon that is blended and bottled at 107 proof, the same as Old Weller Antique. Its suggested retail is in the $50 range but it is not possible to buy at that price...a more typical bill is around $200.
Booker's is a Jim Beam product (the parent company is Beam-Suntory), and is bottled at barrel proof, so each batch is slightly different. Typical ages for Booker's batches range from 7 o 8 years. The batch I'm tasting now, 2015-06 Noe Secret, is 128 proof, aged about seven years. The mash bill is fairly high in rye rather than wheat. It's a $50 bottle, though I've read rumors that Suntory is going to push that up to $100 for upcoming releases...time to stockpile.
If you just read the mash bills and overviews of the two bourbons, one wheat, one rye, you'd think they'd taste pretty different, but I recall thinking after my first sip or two of Booker's, "Wow, that reminds me a lot of Old Rip. I should do a comparison one of these days." Thus this post.
We'll start with the nose. Old Rip is predomiantly butterscotch and vanilla. It's one of the few bourbons that I can identify with my eyes closed. Remember how warm butterscotch pudding smells right off the stove? Add a drop of vanilla, give it a good long inhale, and you've got Old Rip. It's rounder and sweeter than vanilla extract. I've often wondered if there's some additional ingredient in there, since the smell is so unique, but I've not seen any indication that there is.
Booker's is a little different...the astringency of the rye peeks through, and there's a slight orange overtone with a little almond thrown in. At 128 proof there's a significant alcohol overtone as well, so you'll want to open your mouth slightly as you give it a whiff to offset that.
In color, both have a deep golden hue, though Old Rip is slightly darker. Both exhibit the kind of legs you'd expect at these proof levels.
Now for taste. First the Old Rip.
Sorry, I got lost there for a minute. Old Rip is amazingly smooth at 107 proof, and the butterscotch holds for a very long time. It's a little viscous which makes me think that the overall sugar content is a little higher than an average bourbon. There's a bit of bite at the tip of the tongue, then just warm buttery pudding goodness that spreads front to back. The finish lasts a good minute.
Next, the Booker's.
It's high proof, and it bites. For this comparison I didn't water it down to 107 to match the Old Rip. There's less viscosity, less butterscotch, and just a hint of rye astringency. It reminds me a little of crème brûlée, which has a little bit of ashy bitterness from the burnt sugar, and then toffee and orange in the finish, which is quite long...less than Old Rip but not significantly so.
The verdict? Booker's is not Old Rip van Winkle by any stretch, however it is the closest in flavor that I've run across in a $50 bourbon. You can't get Old Rip in your average liquor store...the few bottles that each store receives are allocated well in advance...but Booker's is readily available (at least for now). For sipping, I'd add a little water to get Booker's down to around 110 proof (half an ounce of water or an ice cube for two ounces of bourbon). I wouldn't use Booker's (or Old Rip, for that matter) as a mixer; that's what Weller and other are for. Both have a lovely toffee-butterscotch flavor that is ideal for sipping in front of a warm fire. I pull out the Old Rip on special occasions, but Booker's is almost always in play on my shelf.
One caveat...Old Rip is pretty consistent due to the way it is blended. Booker's is bottled right out of the barrel, and each batch is slightly different. If you find a batch of Booker's that you are simply ga-ga over, grab as many as you can.
Last week The Guardian ran a story that claimed a backdoor was embedded in Facebook's WhatsApp messaging service. Bloggers went nuts as we do when it looks like there's some nefarious code lurking in a popular application, and of course Facebook is a favorite target of everybody. I tweeted my disdain for WhatsApp moments after reading the article, pointing out that when it comes to secure communication, closed-source code just doesn't cut it.
Today Joseph Bonneau and Erica Portnoy over at EFF posted a very good analysis of what WhatsApp is actually doing in this case. It turns out that the purported back door is really a design decision by the WhatsApp team; they are choosing reliability over security. The quick explanation is that if a WhatsApp user changes his or her encryption key, the app will, behind the scenes, re-encrypt a pending message with the new key in order to make sure it is delivered. The intent is to not drop any messages.
Unfortunately, by choosing reliability (no dropped messages), WhatsApp has opened up a fairly large hole in which a malicious third party could spoof a key change and retrieve messages intended for someone else.
EFF's article does a very good job of explaining the risk, but I think it fails to drive home the point that this behavior makes WhatsApp completely unusable for anyone who is depending on secrecy. You won't know that your communication has been compromised until it's already happened.
Signal, the app that WhatsApp is built on, uses a different, secure behavior that will drop the message if a key change is detected.
Casual users of WhatsApp won't care one way or another about this. However, Facebook is promoting the security of WhatsApp and implying that it is as strong as Signal when it in fact isn't. To me this is worse than having no security at all...in that case you at least know exactly what you are getting. It says to me that Facebook's management team doesn't really care about security in WhatsApp and are just using end-to-end encryption as a marketing tool.
Signal has its own problems, but it is the most reliable internet-connected messaging app in popular use right now. I only hope that Facebook's decision to choose convenience over security doesn't get someone hurt.
This post is part of a series on technologies that I’m currently using for privacy, and my reasons for them. You can see the entire list in the first post.
tl;dr: I don't trust anyone with my data except myself, and neither should you.
I think that trust is the single most important commodity on the internet, and the one that is least thought about. In the past four or five years the number of online file storage services (collectively 'the cloud') went from zero to more than I can name. All of them have the same business model: "Trust us with your data."
But that's not the pitch, which is, "Wouldn't you like to have access to your files from any device?"
A large majority of my students use Google Docs for cloud storage. It's free, easy to use, and well integrated into a lot of third-party tools. Google is a household name and most people trust them implicitly. However, as I point out to my students, if they bothered to read the terms of service when they signed up, they know that they are giving permission to Google to scan, index, compile, profile, and otherwise read through the documents that are stored on the Google cloud.
There's nothing nefarious about this; Google is basically an ad agency, and well over half of their revenue is made by selling access to their profiles of each user, which are built by combining search history, emails, and the contents of our documents on their cloud. You agreed to this when you signed up for the service. It's why you start seeing ads for vacations when you send your mom an email about an upcoming trip.
Yes and no. Most cloud services will encrypt the transmission of your file from your computer to theirs, however when the file is at rest on their servers, it might or might not be encrypted, depending on the company. In most cases, if the file is encrypted, it is with the cloud service's key, not yours. That means that if the key is compromised or a law-enforcement or spy agency wants to see what's in the file, the cloud service will decrypt your file for them and turn it over. Warrants, in the form of National Security Letters, come with a gag order and so you will not be told when an agency has requested to see your files.
Some services are better than others about this; Apple says that files are encrypted in transit and at rest on their iCould servers. However, it's my understanding that the files are currently encrypted with Apple's keys, which are subject to FISA warrants. I believe that Apple is working on a solution in which they haven no knowledge of the encryption key.
You should assume that any file you store on someone else's server can be read by someone else.
Given that assumption, if you choose to use a commercial cloud service, the very least you should do is encrypt your files locally and only store the encrypted versions on the cloud.
Another trust issue that isn't brought up much is whether or not the company you are using now to store your files will still be around in a few years. Odds are that Microsoft and Google and Apple will be in business (though we've seen large companies fail before), but what about Dropbox? Box? Evernote? When you store files on any company's servers, you are trusting that they will still be in business in the future.
I don't trust anyone with my data except myself. I do, though, want the convenience of cloud storage. My solution was to build my own personal cloud using Seafile, an open-source cloud server, running on my own Linux-based RAID storage system. My files are under my control, on a machine that I built, using software that I inspected, and encrypted with my own secure keys. The Seafile client runs on any platform, and so my files are always in sync no matter which device (desktop, phone, tablet) I pick up.
The network itself is as secure as I can manage, and I use several automated tools to monitor and manage security, especially around the cloud system.
I will admit that this isn't a system that your grandmother could put together, however it isn't as difficult as you might think; the pieces that you need (Linux server, firewall, RAID array) have become very easy for someone with just a little technical knowledge to set up. There's a docker container for it, and I expect to see a Bitnami kit for it soon; both are one-button deployments.
Using my own cloud service solves all of my trust issues. If I don't trust myself, I have bigger problems than someone reading through my files!
Several manufacturers sell personal cloud appliances, like this one from Western Digital. They all work pretty much the same way; your files are stored locally on the cloud appliance and available on your network to any device. My advice is to avoid appliances that have just one storage drive or use proprietary formats to store files...you are setting up a single point of failure with them.
If you want to access your files anywhere other than your house network, there's a problem: The internet address of your home network isn't readily available. The way that most home cloud appliances solve this is by having you set up an account on their server through which you can access your personal cloud. If you're on the road, you open up the Western Digital cloud app, log on to their server, and through that account gain access to your files.
Well, here's the trust problem again. You now are allowing a third party to keep track of your cloud server and possibly streaming your files through their network. Do you trust them? Worse, these appliances run closed-source, proprietary software and usually come out of the box with automatic updates enabled. If some three-letter agency wanted access to your files, they'd just push an update to your machine with a back door installed. And that's assuming there isn't one already installed...we don't get to see the source code, so there's no way to prove there isn't one.
I would store my non-critical files on this kind of personal server but would assume that anything stored on it was compromised.
The assumption that third parties have access to your files in the cloud, and that you should assume that anything stored in the cloud is compromised, might seem like paranoia, but frankly this is how files should be treated. It's your data, and no one should by default have any access to it whatsoever. We certainly have the technical capability to set up private cloud storage, but there apparently isn't a huge market demand for it or it we'd see more companies step forward.
There are a few, though offering this level of service. Sync, a Canadian firm, looks promising. They seem to embrace zero-knowledge storage, which means that you hold the encryption keys, and they are not able to access your files in any way. They also seem to not store metadata about your files. Other services such as SpiderOak claim the same (in SpiderOak's case only if you only use the desktop client and do not share files with others).
I say 'seem to' and 'claim to' because the commercial providers of zero-knowledge storage are closed-source...the only real evidence we have to back up their claims is that they say it is so. I would not trust these companies with any sensitive files, but I might use them for trivial data. I trust Seafile because I've personally examined the source code and compiled it on my own machines.
I can't discount the convenience of storing data in the cloud. It's become such a significant part of my own habits that I don't even notice it any more...I take it for granted that I can walk up to any of my devices and everything I'm working on is just there, always. It would be a major adjustment for me to go back to pre-cloud work habits.
I have the advantage of having the technical skills and enough healthy skepticism to do all of this myself in a highly secure way. I understand that the average user doesn't, and that this shouldn't prevent them from embracing and using the cloud in their own lives.
To those I offer this advice: Be deliberate about what you store on commercial cloud services and appliances. Understand and act on the knowledge that once a file leaves your possession you lose control of it. Assume that it is being looked at. Use this knowledge to make an informed decision about what you will and will not store in the cloud.
A recent post on CNet describing the author's Hackintosh build made me reflect on a few things that I've done lately that are slowly sliding me away from Apple's ecosystem. Let me start by saying that I've been an Apple fanboy for many years; pretty much every piece of tech I use is either an Apple product or created by an ex-Apple employee. Though I do use a fair number of Linux machines for server-side work, there's a big fat apple on everything else. Heck, I was the Technical Editor of inCider Magazine back in the mid-80s, writing articles about how to homebrew Apple II add-ons. I completely bought in to the Apple-centric world view of the past 8 to 10 years.
That said, I feel like the hold that Apple has on me is slipping. Here are three events in the past month that make me wonder what's coming next:
Like Ian Sherr of CNet, I watched the October Apple product announcement very closely. I was ready to spend money on a new office computer and wanted to see what the new Macbook Pros and iMacs looked like before making a decision. To say that I was disappointed is an understatement. The touchbar on the new MacBook is interesting, but the rest of the specs are horrific given the price point. If you separate out the operating system, MacBooks look a lot like laptops from other manufacturers, except that the MacBooks use very conservative CPUs, graphic cards, memory, and the like.
After watching the announcement I order the parts I needed for a high-end Hackintosh, which was still $1,000 to $1,500 less than the MacBook. I tend to build a lot of Hackintoshes, but in this case I was willing to see what Apple had in mind. There was no upgrade to the iMac, no upgrade to the Pro, no upgrade to the Mini. Hackintosh it was.
Next up was the Amazon Echo Dot and the Alexa service. Now, I love using Siri on my phone and watch (and now my Mac) but it only took a few days of using Alexa to realize that Amazon had completely eaten Apple's lunch on voice-enabled apps. There's just no comparison; Alexa is a generation ahead of Apple's Siri. There are a lot of things that Alexa can't yet do, but once those few things are in place Amazon will own this space. I'm using Siri less and less and finding ways to replace Siri with Alexa in my daily workflow. As an example, I used to use Siri as the primary way to manage my grocery list. Now, Alexa handles creation of the list because it is so much more efficient, and Siri (via IFTTT) is just used to display the list on my watch at the store. At this point Siri is nearly unused.
The final bit was today. I wanted to be able to query Alexa about my schedule, but my calendars were hosted on iCloud. I couldn't sync the iCloud calendars with Google Calendar, which is what Alexa needs. I just spent about 15 minutes moving all of my calendars (about a dozen) to Google, off of iCloud, which is one more step away from Apple's ecosystem.
I'm not abandoning MacS or iOS (or WatchOS or tvOS or any other Apple OS); I really do believe that they are technically superior, and I trust them more from a privacy standpoint than any other solution outside Linux. And I do understand that by handing Google my calendars I'm also handing them any personal information that might be in those appointments. (Which is why I keep a non-shared calendar locally for sensitive items). But I'm also not going to blindly follow Apple down whatever path they are heading when there are better solutions available.
This post is part of a series on technologies that I'm currently using for privacy, and my reasons for them. You can see the entire list in the first post.
Email privacy is a tough nut to crack. To start, the protocol that's used to move email around the internet, SMTP, is extremely simple and text-based. Email messages themselves are typically moved and stored as plain text. You know those fancy T0: and From: and Subject: fields that you see on every email message? They are just text...the email client you are using formats them based on the name. It's trivial to forge emails to look like they are coming from someone else. Here's an Instructable on how to do it.
Note that there are parts of the email transaction that are more difficult to forge, but if the target is an average user, it probably isn't necessary to worry about those bits.
To provide some modicum of privacy for emails, many of us bolt on PGP encryption, which encrypts the email, or digitally signs it, or both. Note that the encryption covers just the body of the email message...the subject, to, from, and other headers are not encrypted, which means that a fair amount of metadata is being sent in the clear.
PGP is a strong solution for personal encryption. Unfortunately it is exceptionally difficult for the average user to set up and maintain. Even geeks have trouble with it. I've discussed my changing attitude toward PGP here in the blog, and many technologists who I respect highly are starting to turn away from it in favor of simpler, transactional, message-based systems like Signal.
The tldr; of my own post is that I will continue to use PGP to digitally sign my outgoing email (as I have been doing for many years) but will move to Signal for secure conversations. The PGP signature provides nonrepudiation to me, which is to say that I can prove whether or not a message was sent by me and whether is was altered once it left my hands.
So, I'm sticking with PGP and email.
But here's the rub. I'm a Mac user, and MacOS Mail doesn't support PGP. Worse, there's no Apple supported API for Mail. There's a project maintained by the folks at GPGTools that provides a plugin for Mail, however the method they use is to reverse-engineer each release of Mail to try to wedge their code in. This worked for a while, but the Sierra release of MacOS completely broke the plugin, and it's not clear if it will ever work again.
Since I still want to use PGP to digitally sign my email, I've transitioned to Mozilla's Thunderbird client. It is slightly less friendly than Apple Mail, but it does fully support plugins that provide PGP tools for both encryption and signing. I'm actually finding it to be a little more flexible than Apple Mail with filters and rules. Enigmail is the plugin that I'm using and it seems pretty straightforward.
If you are Windows user and have found a good solution, please send me a note and I'll update this post for our Windows readers.
Filippo Valsorda wrote an article recently on ArsTechnica titled I'm Throwing in the Towel on PGP, and I Work in Security that really made me think. Filippo is the real deal when it comes to PGP; few have his bona fides in the security arena, and when he talks, people should listen.
The basic message of the article is the same one that we've been hearing for two decades: PGP is hard to use. I've been a proponent since 1994 or so, when I first downloaded PGP. I contributed to Phil Zimmerman's defense fund (and have the T-shirt somewhere in my attic to prove it). As an educator I've discussed PGP and how it works with nearly every class I've taught in the past 20 years. I push it really hard.
And yet, like Filippo, I receive two, maybe three encrypted emails each year, often because I initiated the encrypted conversation. Clearly there's an issue here.
Most stock email clients don't support PGP. Mail on MacOS doesn't. I'm pretty sure that Outlook doesn't. I use Thunderbird because it does support PGP via a plugin. I really don't get this...email should be encrypted by default in a simple, transparent way by every major email client. Key generation should be done behind the scenes so that the user doesn't have to even think about it.
We might not ever get there.
And so, after 20 years of trying to convince everyone I meet that they should be using encryption, I, like Filippo, might be done.
However, there is a use case that I think works, and that I will use myself and educate others about. I've digitally signed every email that I send using PGP for several years, and I think that it might be the right way to think about how we use PGP. Here's the approach, which is similar to what Filippo is thinking:
Nonrepudiation is really a benefit to me rather than anyone receiving my messages and I don't see any reason not to use my published keys for this.
Secure apps like Signal I think are more natural than bolting PGP onto email and are easier for non-tenchical users to understand. Further, the lack of forward secrecy in PGP (and its inclusion in Signal) should make us think twice about encrypting conversations over and over with the same keys rather than using a new set of keys for each conversation.
I think this approach will do for the time being.
[Update: Neil Walfield posted his response to Filippo's article; the comments are a good read on the problems we're facing with PGP. ]