Research
Our research spans on multiple areas of data-centric systems. Recently, we have been working on developing practical solutions for private collaborative analytics with Multi-Party Computation, designing adaptive systems for data stream processing, and scaling graph Machine Learning on modern hardware.
Systems for Secure Computation
Research in the cryptography community has shown that any function can be securely computed by a group of participants in a distributed fashion such that each party learns the function’s output and nothing more. This fascinating idea started as a theoretical curiosity in the 1980s but since then it has evolved into a useful tool to realize use cases like the gender wage gap study in the Boston area. A series of recent theoretical advances in the field have further supported the belief that provably secure computation can perhaps become as practical and ubiquitous as public-key cryptography. Some of these advances include efficient multi-party computation protocols, fully homomorphic encryption schemes, zero-knowledge proofs, and oblivious RAM. Supporting end-to-end secure computation with practical performance requires rethinking the entire systems stack: from the programming abstractions all the way down to the hardware. Below are two recent results of our research in this area.
Secure relational analytics
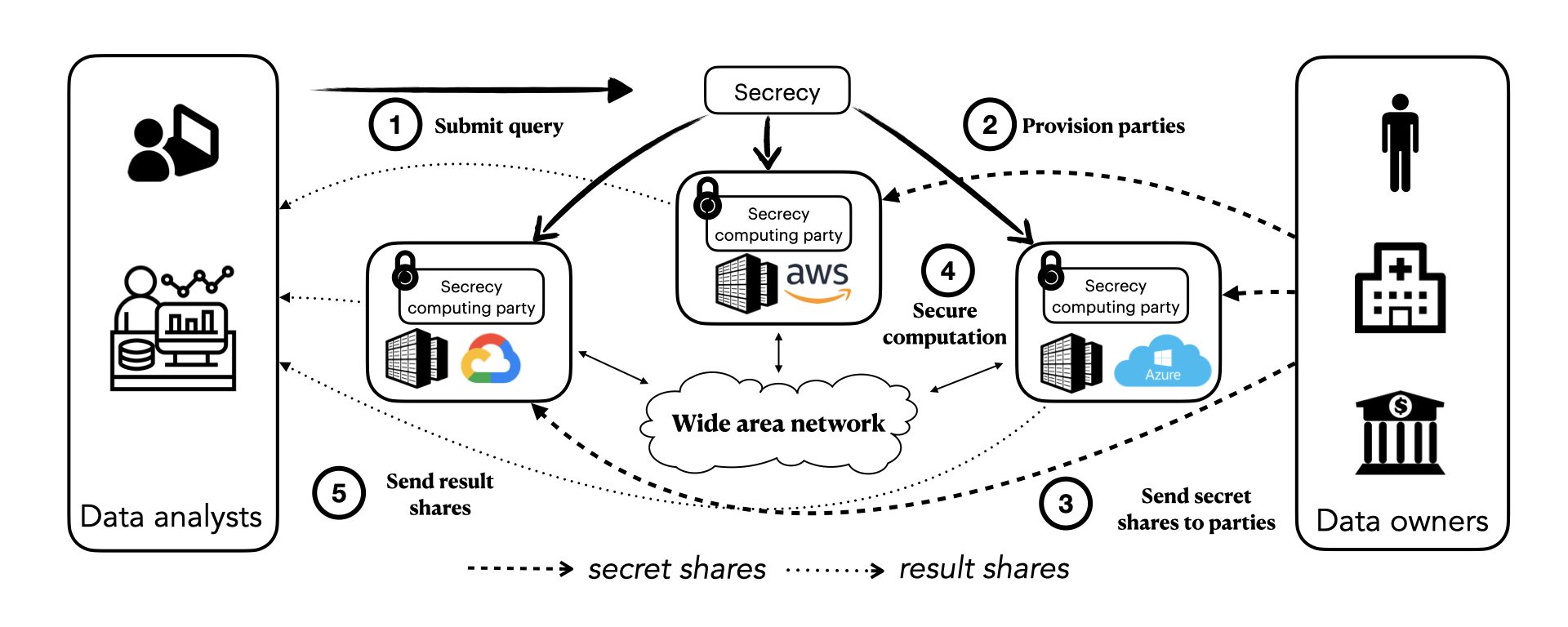
SECRECY (NSDI’23) is a novel system for privacy-preserving collaborative analytics as a service. SECRECY allows multiple data holders to contribute their data towards a joint analysis in the cloud, while keeping the data siloed even from the cloud providers. At the same time, it enables cloud providers to offer their services to clients who would have otherwise refused to perform a computation altogether or insisted that it be done on private infrastructure. SECRECY ensures no information leakage and provides provable security guarantees by employing cryptographically secure Multi-Party Computation (MPC). SECRECY’s core novelty is a generic cost-based optimization framework for relational MPC that does not rely on trusted infrastructure.
Read the paper for more details.
ORQ (SOSP’25), the Oblivious Relational Query engine, significantly improves the performance and expressivity of SECRECY for secure collaborative analytics in the outsourced setting. We introduce a new join operator and implement more efficient sorting protocols which allow us to evaluate unique-key joins in O(n log n) time, rather than O(n²). From there, we show how query rewriting under relational algebra allows the vast majority of practical queries — even those with arbitrary joins — to be evaluated by our join operator. ORQ runs the entire TPC-H benchmark, for the first time under MPC, and executes all queries from prior work significantly faster and orders-of-magnitude larger inputs. ORQ also supports multiple MPC protocols and threat models; we hope it will serve as the foundation for future research in secure computation beyond relational analytics.
For more details, see the paper and our open-source codebase.
Secure time series analytics
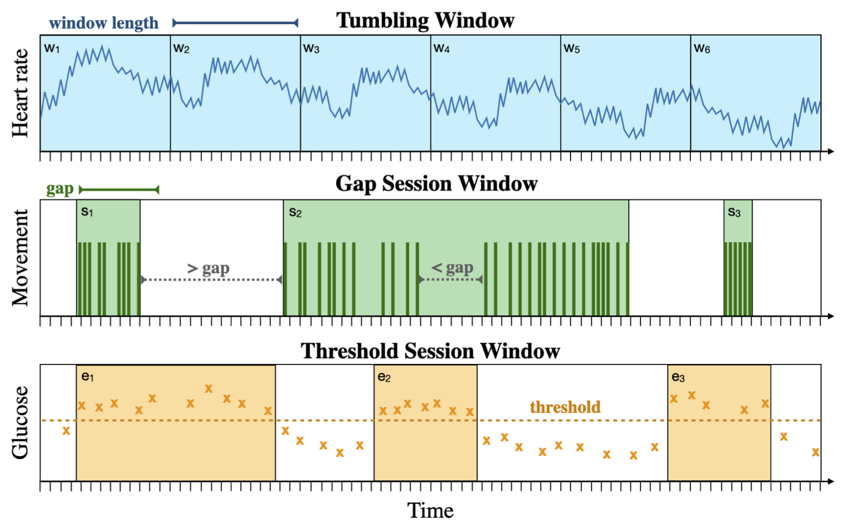
TVA (Security’23) is a novel system for secure and expressive time series analysis under MPC. Similarly to SECRECY, TVA protects data by distributing trust and generalizes the functionality of prior systems without compromising security or performance. To mitigate the tension between these two, TVA employs new protocols, cross-layer optimizations, and vectorized primitives that enable it to scale to large datasets with modest use of resources. TVA is the first system to support arbitrary composition of oblivious time window operators, keyed aggregations, and multiple filter predicates, while keeping all data attributes private, including record timestamps and user-defined values in query predicates.
Read our paper for more details.
Adaptive Data Stream Processing Systems
The success of open-source streaming dataflow systems, like Apache Flink and Spark Streaming, has generated a vibrant ecosystem of applications, including online content recommendation, continuous traffic monitoring, complex event processing, anomaly detection, and data enrichment for online model predictions. However, the increasing diversity of workloads combined with the emergence of compute-enabled edge devices, hardware accelerators, and new cloud computing paradigms, is pushing these decade-old frameworks to their limits.

Our research objective is to develop next-generation stream processing systems that treat adaptability, resource efficiency, and platform independence as first-class concerns. We envision stream processing technology that is easily accessible to non-expert users, so that the cost and complexity of deploying streaming analytics is no longer a barrier to scientists, doctors, governments, and small organizations. To this end, our recent work has focused on addressing the challenge of automatic reconfiguration under workload variance (CAPSys at EuroSys’25, The non-expert tax at BiDEDE’22) and exploiting workload characterization to improve the efficiency of stateful dataflow computations (Workload-aware state management at HotSorage’20, Gadget benchmark harness at EuroSys’22).

We have also recently received an NSF CAREER award that will allow us to conduct fundamental research towards developing a novel streaming dataflow software stack, tailored to the heterogeneity of emerging workloads and computing environments.
Scaling Graph ML on Modern Storage
Graph Neural Networks (GNNs) are a powerful model for performing machine learning tasks on graph-structured data. GNNs have demonstrated excellent performance on a variety of prediction and classification scenarios, such as recommendation, fraud detection, search, molecular biology, and code summarization. In these application domains, graphs are often massive, consisting of billions of edges and rich vertex attributes, and may not fit in the main memory of a single machine. Further, real-world graphs are dynamic, thus, models need to be continually updated as the underlying network changes. These characteristics pose a grand challenge to the design of GNN frameworks and require fundamental research on innovative systems for scalable and cost-efficient graph machine learning. Existing GNN systems are resource-intensive, employing distributed computation and requiring large amounts of memory and access to multiple GPUs. As a result, large-scale GNN models are inaccessible to users with modest resources and researchers outside of industrial environments.
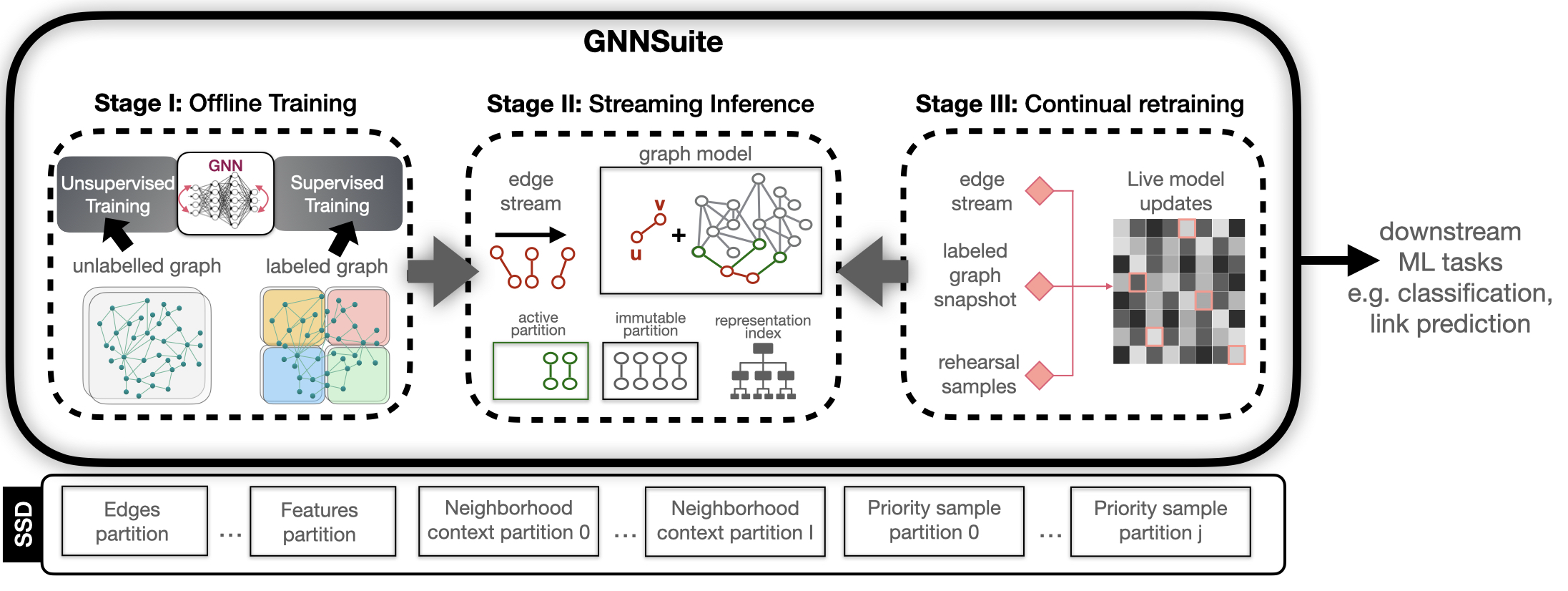
We have recently received an NSF award that will allow us to address the requirements of large-scale graph ML workloads by harnessing emerging storage technology. Specifically, we are working on designing and implementing innovative systems for static and dynamic GNNs that target a single commodity machine with SSD storage. Leveraging the large capacity, substantial bandwidth, low access latency, and on-device computational capabilities of modern SSDs, we aim to develop the necessary systems infrastructure to provide a viable and cost-effective alternative to distributed GNN architectures.
One of our recent results is a novel GNN sampling approach that harnesses near-storage compute technology to achieve efficient large-scale GNN training. Our DAMON’24 paper describes the implementation of our high-throughput, epoch-wide sampling FPGA kernel that enables pipelining across training epochs.