SCH: INT: Distributed Analytics for Enhancing Fertility in Families
Funding Agency: National Science Foundation (NSF) and National Institutes of Health (NIH).
Award Number: IIS-1914792
Principal Investigators: Yannis Paschalidis, Alex Olshevsky, and Lauren Wise at Boston University, and Shruthi Mahalingaiah at Harvard.
PROJECT ABSTRACT
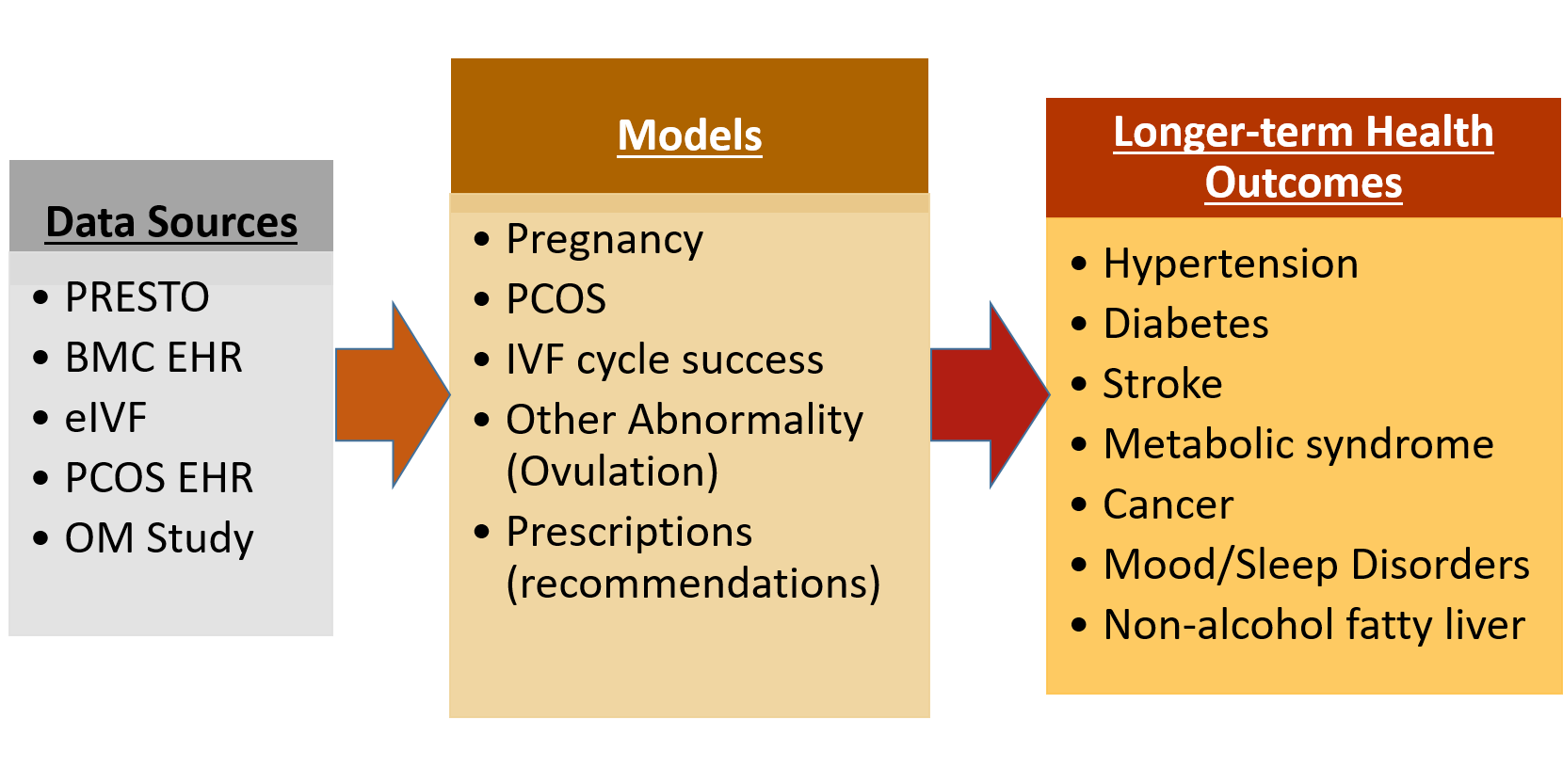 The demands of modern life, education and career choices, as well as the availability of assisted reproductive technologies, are leading many individuals and couples to delay childbearing. This has contributed to infertility and sub-fertility emerging as significant public health problems in the U.S., affecting about 15% of couples, involving both men and women, and resulting to more than $5 billion spent annually in infertility services. Such costs are often not covered by health insurance and, consequently, generate access disparities. This project will leverage information from self-administered surveys and medical records to produce highly accurate personalized predictions regarding fertility potential, pregnancy, the success of an In Vitro Fertilization cycle, and the presence of specific reproductive health issues affecting fertility. In addition to predictions, the project will develop methods to generate personalized recommendations, empowering individuals and their physicians to make the most appropriate, individualized health care decisions. The work is in line with the emergence of personalized medicine, aided by data and algorithmic advances. The project will train engineering and computer science graduate students to contribute to medical informatics, involve undergraduate and high school students, impact educational offerings, and, by using data from a safety-net hospital, help understand socioeconomic disparities in the use of infertility treatment services.
The demands of modern life, education and career choices, as well as the availability of assisted reproductive technologies, are leading many individuals and couples to delay childbearing. This has contributed to infertility and sub-fertility emerging as significant public health problems in the U.S., affecting about 15% of couples, involving both men and women, and resulting to more than $5 billion spent annually in infertility services. Such costs are often not covered by health insurance and, consequently, generate access disparities. This project will leverage information from self-administered surveys and medical records to produce highly accurate personalized predictions regarding fertility potential, pregnancy, the success of an In Vitro Fertilization cycle, and the presence of specific reproductive health issues affecting fertility. In addition to predictions, the project will develop methods to generate personalized recommendations, empowering individuals and their physicians to make the most appropriate, individualized health care decisions. The work is in line with the emergence of personalized medicine, aided by data and algorithmic advances. The project will train engineering and computer science graduate students to contribute to medical informatics, involve undergraduate and high school students, impact educational offerings, and, by using data from a safety-net hospital, help understand socioeconomic disparities in the use of infertility treatment services.
The predictive and prescriptive models developed in this project will be based on a number of advances in machine learning and analytics, including: (i) new predictive models that handle both continuous and discrete outcomes, are robust to outliers, produce highly accurate personalized predictions, and enable outlier detection; (ii) novel prescriptive models that optimally select from a menu of choices to make recommendations that yield health-centered outcomes; and (iii) natural language processing methods to process clinical reports, culling critical information that can be used to enhance predictive models. To learn from data, the work will develop new distributed optimization and federated learning methods that can train models through interactions among individual data-holding nodes, such as hospital systems, clouds of smartphone applications, existing prospective cohorts, and personal health records. This distributed paradigm does not require data-holding nodes to share raw data, thus enhancing privacy and security.