
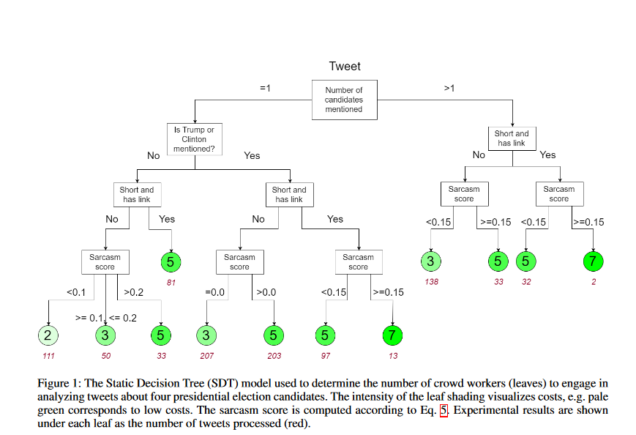
Dynamic Allocation of Crowd Contributions for Sentiment Analysis during the 2016 U.S. Presidential Election
Abstract
Opinions about the 2016 U.S. Presidential Candidates have been expressed in millions of tweets that are challenging to analyze automatically. Crowdsourcing the analysis of political tweets effectively is also difficult, due to large inter-rater disagreements when sarcasm is involved. Each tweet is typically analyzed by a fixed number of workers and majority voting. We here propose a crowdsourcing framework that instead uses a dynamic allocation of the number of workers. We explore two dynamic-allocation methods: (1) The number of workers queried to label a tweet is computed offline based on the predicted difficulty of discerning the sentiment of a particular tweet. (2) The number of crowd workers is determined online, during an iterative crowd sourcing process, based on inter-rater agreements between labels. We applied our approach to 1,000 twitter messages about the four U.S. presidential candidates Clinton, Cruz, Sanders, and Trump, collected during February 2016. We implemented the two proposed methods using decision trees that allocate more crowd efforts to tweets predicted to be sarcastic. We show that our framework outperforms the traditional static allocation scheme. It collects opinion labels from the crowd at a much lower cost while maintaining labeling accuracy.
 |
Cite the paper: