Category: Tools
What I’m Using for Privacy: Cloud
This post is part of a series on technologies that I’m currently using for privacy, and my reasons for them. You can see the entire list in the first post.
tl;dr: I don’t trust anyone with my data except myself, and neither should you.
If you aren’t paying for it, you are the product
I think that trust is the single most important commodity on the internet, and the one that is least thought about. In the past four or five years the number of online file storage services (collectively ‘the cloud’) went from zero to more than I can name. All of them have the same business model: “Trust us with your data.”
But that’s not the pitch, which is, “Wouldn’t you like to have access to your files from any device?”
A large majority of my students use Google Docs for cloud storage. It’s free, easy to use, and well integrated into a lot of third-party tools. Google is a household name and most people trust them implicitly. However, as I point out to my students, if they bothered to read the terms of service when they signed up, they know that they are giving permission to Google to scan, index, compile, profile, and otherwise read through the documents that are stored on the Google cloud.
There’s nothing nefarious about this; Google is basically an ad agency, and well over half of their revenue is made by selling access to their profiles of each user, which are built by combining search history, emails, and the contents of our documents on their cloud. You agreed to this when you signed up for the service. It’s why you start seeing ads for vacations when you send your mom an email about an upcoming trip.
But isn’t my data encrypted?
Yes and no. Most cloud services will encrypt the transmission of your file from your computer to theirs, however when the file is at rest on their servers, it might or might not be encrypted, depending on the company. In most cases, if the file is encrypted, it is with the cloud service’s key, not yours. That means that if the key is compromised or a law-enforcement or spy agency wants to see what’s in the file, the cloud service will decrypt your file for them and turn it over. Warrants, in the form of National Security Letters, come with a gag order and so you will not be told when an agency has requested to see your files.
Some services are better than others about this; Apple says that files are encrypted in transit and at rest on their iCould servers. However, it’s my understanding that the files are currently encrypted with Apple’s keys, which are subject to FISA warrants. I believe that Apple is working on a solution in which they haven no knowledge of the encryption key.
You should assume that any file you store on someone else’s server can be read by someone else.
Given that assumption, if you choose to use a commercial cloud service, the very least you should do is encrypt your files locally and only store the encrypted versions on the cloud.
And….they’re gone
Another trust issue that isn’t brought up much is whether or not the company you are using now to store your files will still be around in a few years. Odds are that Microsoft and Google and Apple will be in business (though we’ve seen large companies fail before), but what about Dropbox? Box? Evernote? When you store files on any company’s servers, you are trusting that they will still be in business in the future.
My personal solution
I don’t trust anyone with my data except myself. I do, though, want the convenience of cloud storage. My solution was to build my own personal cloud using Seafile, an open-source cloud server, running on my own Linux-based RAID storage system. My files are under my control, on a machine that I built, using software that I inspected, and encrypted with my own secure keys. The Seafile client runs on any platform, and so my files are always in sync no matter which device (desktop, phone, tablet) I pick up.
The network itself is as secure as I can manage, and I use several automated tools to monitor and manage security, especially around the cloud system.
I will admit that this isn’t a system that your grandmother could put together, however it isn’t as difficult as you might think; the pieces that you need (Linux server, firewall, RAID array) have become very easy for someone with just a little technical knowledge to set up. There’s a docker container for it, and I expect to see a Bitnami kit for it soon; both are one-button deployments.
Using my own cloud service solves all of my trust issues. If I don’t trust myself, I have bigger problems than someone reading through my files!
What about ‘personal’ clouds?
Several manufacturers sell personal cloud appliances, like this one from Western Digital. They all work pretty much the same way; your files are stored locally on the cloud appliance and available on your network to any device. My advice is to avoid appliances that have just one storage drive or use proprietary formats to store files…you are setting up a single point of failure with them.
If you want to access your files anywhere other than your house network, there’s a problem: The internet address of your home network isn’t readily available. The way that most home cloud appliances solve this is by having you set up an account on their server through which you can access your personal cloud. If you’re on the road, you open up the Western Digital cloud app, log on to their server, and through that account gain access to your files.
Well, here’s the trust problem again. You now are allowing a third party to keep track of your cloud server and possibly streaming your files through their network. Do you trust them? Worse, these appliances run closed-source, proprietary software and usually come out of the box with automatic updates enabled. If some three-letter agency wanted access to your files, they’d just push an update to your machine with a back door installed. And that’s assuming there isn’t one already installed…we don’t get to see the source code, so there’s no way to prove there isn’t one.
I would store my non-critical files on this kind of personal server but would assume that anything stored on it was compromised.
Paranoia, big destroyah
The assumption that third parties have access to your files in the cloud, and that you should assume that anything stored in the cloud is compromised, might seem like paranoia, but frankly this is how files should be treated. It’s your data, and no one should by default have any access to it whatsoever. We certainly have the technical capability to set up private cloud storage, but there apparently isn’t a huge market demand for it or it we’d see more companies step forward.
There are a few, though offering this level of service. Sync, a Canadian firm, looks promising. They seem to embrace zero-knowledge storage, which means that you hold the encryption keys, and they are not able to access your files in any way. They also seem to not store metadata about your files. Other services such as SpiderOak claim the same (in SpiderOak’s case only if you only use the desktop client and do not share files with others).
I say ‘seem to’ and ‘claim to’ because the commercial providers of zero-knowledge storage are closed-source…the only real evidence we have to back up their claims is that they say it is so. I would not trust these companies with any sensitive files, but I might use them for trivial data. I trust Seafile because I’ve personally examined the source code and compiled it on my own machines.
Bottom line
I can’t discount the convenience of storing data in the cloud. It’s become such a significant part of my own habits that I don’t even notice it any more…I take it for granted that I can walk up to any of my devices and everything I’m working on is just there, always. It would be a major adjustment for me to go back to pre-cloud work habits.
I have the advantage of having the technical skills and enough healthy skepticism to do all of this myself in a highly secure way. I understand that the average user doesn’t, and that this shouldn’t prevent them from embracing and using the cloud in their own lives.
To those I offer this advice: Be deliberate about what you store on commercial cloud services and appliances. Understand and act on the knowledge that once a file leaves your possession you lose control of it. Assume that it is being looked at. Use this knowledge to make an informed decision about what you will and will not store in the cloud.
Sliding out of the Apple ecosystem?
A recent post on CNet describing the author's Hackintosh build made me reflect on a few things that I've done lately that are slowly sliding me away from Apple's ecosystem. Let me start by saying that I've been an Apple fanboy for many years; pretty much every piece of tech I use is either an Apple product or created by an ex-Apple employee. Though I do use a fair number of Linux machines for server-side work, there's a big fat apple on everything else. Heck, I was the Technical Editor of inCider Magazine back in the mid-80s, writing articles about how to homebrew Apple II add-ons. I completely bought in to the Apple-centric world view of the past 8 to 10 years.
That said, I feel like the hold that Apple has on me is slipping. Here are three events in the past month that make me wonder what's coming next:
Like Ian Sherr of CNet, I watched the October Apple product announcement very closely. I was ready to spend money on a new office computer and wanted to see what the new Macbook Pros and iMacs looked like before making a decision. To say that I was disappointed is an understatement. The touchbar on the new MacBook is interesting, but the rest of the specs are horrific given the price point. If you separate out the operating system, MacBooks look a lot like laptops from other manufacturers, except that the MacBooks use very conservative CPUs, graphic cards, memory, and the like.
After watching the announcement I order the parts I needed for a high-end Hackintosh, which was still $1,000 to $1,500 less than the MacBook. I tend to build a lot of Hackintoshes, but in this case I was willing to see what Apple had in mind. There was no upgrade to the iMac, no upgrade to the Pro, no upgrade to the Mini. Hackintosh it was.
Next up was the Amazon Echo Dot and the Alexa service. Now, I love using Siri on my phone and watch (and now my Mac) but it only took a few days of using Alexa to realize that Amazon had completely eaten Apple's lunch on voice-enabled apps. There's just no comparison; Alexa is a generation ahead of Apple's Siri. There are a lot of things that Alexa can't yet do, but once those few things are in place Amazon will own this space. I'm using Siri less and less and finding ways to replace Siri with Alexa in my daily workflow. As an example, I used to use Siri as the primary way to manage my grocery list. Now, Alexa handles creation of the list because it is so much more efficient, and Siri (via IFTTT) is just used to display the list on my watch at the store. At this point Siri is nearly unused.
The final bit was today. I wanted to be able to query Alexa about my schedule, but my calendars were hosted on iCloud. I couldn't sync the iCloud calendars with Google Calendar, which is what Alexa needs. I just spent about 15 minutes moving all of my calendars (about a dozen) to Google, off of iCloud, which is one more step away from Apple's ecosystem.
I'm not abandoning MacS or iOS (or WatchOS or tvOS or any other Apple OS); I really do believe that they are technically superior, and I trust them more from a privacy standpoint than any other solution outside Linux. And I do understand that by handing Google my calendars I'm also handing them any personal information that might be in those appointments. (Which is why I keep a non-shared calendar locally for sensitive items). But I'm also not going to blindly follow Apple down whatever path they are heading when there are better solutions available.
What I’m Using for Privacy: Email
This post is part of a series on technologies that I'm currently using for privacy, and my reasons for them. You can see the entire list in the first post.
Email privacy is a tough nut to crack. To start, the protocol that's used to move email around the internet, SMTP, is extremely simple and text-based. Email messages themselves are typically moved and stored as plain text. You know those fancy T0: and From: and Subject: fields that you see on every email message? They are just text...the email client you are using formats them based on the name. It's trivial to forge emails to look like they are coming from someone else. Here's an Instructable on how to do it.
Note that there are parts of the email transaction that are more difficult to forge, but if the target is an average user, it probably isn't necessary to worry about those bits.
To provide some modicum of privacy for emails, many of us bolt on PGP encryption, which encrypts the email, or digitally signs it, or both. Note that the encryption covers just the body of the email message...the subject, to, from, and other headers are not encrypted, which means that a fair amount of metadata is being sent in the clear.
PGP is a strong solution for personal encryption. Unfortunately it is exceptionally difficult for the average user to set up and maintain. Even geeks have trouble with it. I've discussed my changing attitude toward PGP here in the blog, and many technologists who I respect highly are starting to turn away from it in favor of simpler, transactional, message-based systems like Signal.
The tldr; of my own post is that I will continue to use PGP to digitally sign my outgoing email (as I have been doing for many years) but will move to Signal for secure conversations. The PGP signature provides nonrepudiation to me, which is to say that I can prove whether or not a message was sent by me and whether is was altered once it left my hands.
So, I'm sticking with PGP and email.
But here's the rub. I'm a Mac user, and MacOS Mail doesn't support PGP. Worse, there's no Apple supported API for Mail. There's a project maintained by the folks at GPGTools that provides a plugin for Mail, however the method they use is to reverse-engineer each release of Mail to try to wedge their code in. This worked for a while, but the Sierra release of MacOS completely broke the plugin, and it's not clear if it will ever work again.
Since I still want to use PGP to digitally sign my email, I've transitioned to Mozilla's Thunderbird client. It is slightly less friendly than Apple Mail, but it does fully support plugins that provide PGP tools for both encryption and signing. I'm actually finding it to be a little more flexible than Apple Mail with filters and rules. Enigmail is the plugin that I'm using and it seems pretty straightforward.
If you are Windows user and have found a good solution, please send me a note and I'll update this post for our Windows readers.
Rethinking PGP encryption
Filippo Valsorda wrote an article recently on ArsTechnica titled I'm Throwing in the Towel on PGP, and I Work in Security that really made me think. Filippo is the real deal when it comes to PGP; few have his bona fides in the security arena, and when he talks, people should listen.
The basic message of the article is the same one that we've been hearing for two decades: PGP is hard to use. I've been a proponent since 1994 or so, when I first downloaded PGP. I contributed to Phil Zimmerman's defense fund (and have the T-shirt somewhere in my attic to prove it). As an educator I've discussed PGP and how it works with nearly every class I've taught in the past 20 years. I push it really hard.
And yet, like Filippo, I receive two, maybe three encrypted emails each year, often because I initiated the encrypted conversation. Clearly there's an issue here.
Most stock email clients don't support PGP. Mail on MacOS doesn't. I'm pretty sure that Outlook doesn't. I use Thunderbird because it does support PGP via a plugin. I really don't get this...email should be encrypted by default in a simple, transparent way by every major email client. Key generation should be done behind the scenes so that the user doesn't have to even think about it.
We might not ever get there.
And so, after 20 years of trying to convince everyone I meet that they should be using encryption, I, like Filippo, might be done.
However, there is a use case that I think works, and that I will use myself and educate others about. I've digitally signed every email that I send using PGP for several years, and I think that it might be the right way to think about how we use PGP. Here's the approach, which is similar to what Filippo is thinking:
- I will continue to use PGP signatures on all of my email. This provides nonrepudiation to me. I will use my standard, well-known key pair to sign messages.
- When I need to move an email conversation into encryption, I'll generate a new key pair just for that conversation. The key will be confirmed either via my well-known key pair or via a second channel (Signal IM or similar). The conversation-specific keys will be revoked once the conversation is done.
- I will start to include secure messaging ala Signal in my discussions of privacy
Nonrepudiation is really a benefit to me rather than anyone receiving my messages and I don't see any reason not to use my published keys for this.
Secure apps like Signal I think are more natural than bolting PGP onto email and are easier for non-tenchical users to understand. Further, the lack of forward secrecy in PGP (and its inclusion in Signal) should make us think twice about encrypting conversations over and over with the same keys rather than using a new set of keys for each conversation.
I think this approach will do for the time being.
[Update: Neil Walfield posted his response to Filippo's article; the comments are a good read on the problems we're facing with PGP. ]
Using Javascript Promises to synchronize asynchronous methods
The asynchronous, non-blocking Javascript runtime can be a real challenge for those of us who are used to writing in a synchronous style in languages such as Python of Java. Especially tough is when we need to do several inherently asynchronous things in a particular order...maybe a filter chain...in which the result of a preceding step is used in the next. The typical JS approach is to nest callbacks, but this leads to code that can be hard to maintain.
The following programs illustrate the problem and work toward a solution. In each, the leading comments describe the approach and any issues that it creates. The final solution can be used as a pattern to solve general synchronization problems in Javascript. The formatting options in the BU WordPress editor are a little limited, so you might want to cut and paste each example into your code editor for easier reading.
1. The problem
/*
If you are used to writing procedural code in a language like Python, Java, or C++,
you would expect this code to print step1, step2, step3, and so on. Because Javascript
is non-blocking, this isn't what happens at all. The HTTP requests take time to execute,
and so the JS runtime moves the call to a queue and just keeps going. Once all of the calls on the
main portion of the call stack are complete, an event loop visits each of the completed request()s
in the order they completed and executes their callbacks.
Starting demo
Finished demo
step3: UHub
step2: CNN
step1: KidPub
So what if we need to execute the requests in order, maybe to build up a result from each of them?
*/
var request = require('request');
var step1 = function (req1) {
request(req1, function (err, resp) {
console.log('step1: KidPub');
});
};
var step2 = function (req2) {
request(req2, function (err, resp) {
console.log('step2: CNN');
});
};
var step3 = function(req3) {
request(req3, function (err, resp) {
console.log('step3: UHub');
});
};
console.log('Starting demo');
step1('http://www.kidpub.com');
step2('http://www.cnn.com');
step3('http://universalhub.com');
console.log('Finished demo');
2. Callbacks work just fine, but...
/*
This is the classic way to synchronize things in Javascript using callbacks. When each
request completes, its callback is executed. The callback is still placed in the
event queue, which is why this code prints
Starting demo
Finished demo
step1: BU
step2: CNN
step3: UHub
There's nothing inherently wrong with this approach, however it can lead to what is
called 'callback hell' or the 'pyramid of doom' when the number of synchronized items grows too large.
*/
var request = require('request');
var req1 = 'http://www.bu.edu'; var req2 = 'http://www.cnn.com'; var req3 = 'http://universalhub.com';
var step1 = function () {
request(req1, function (err, resp) {
console.log('step1: BU');
request(req2, function (err, resp) {
console.log('step2: CNN');
request(req3, function(err,resp) {
console.log('step3: UHub');
})
})
});
};
console.log('Starting demo');
step1();
console.log('Finished demo');
3. Promises help solve the problem, but there's a gotcha to watch out for.
/*
One way to avoid callback hell is to use thenables (pronounced THEN-ables), which essentially
implement the callback in a separate function, as described in the Promise/A+ specification.
A Javascript Promise is a value that can be returned that will be filled in or completed at some
future time. Most libraries can be wrapped with a Promise interface, and many implement Promises
natively. In the code here we're using the request-promise library, which wraps the standard HTTP
request library with a Promise interface. The result is code that is much easier to read...an
event happens, THEN another event happes, THEN another and so on.
This might seem like a perfectly reasonable approach, chaining together
calls to external APIs in order to build up a final result.
The problem here is that a Promise is returned by the rp() call in each step...we are
effectively nesting Promises. The code below appears to work, since
it prints the steps on the console in the correct order. However, what's
really happening is that each rp() does NOT complete before moving on to
its console.log(). If we move the console.log() statements inside the callback for
the rp() you'll see them complete out of order, as I've done in step 2. Uncomment the
console.log() and you'll see how it starts to unravel.
*/
var rp = require('request-promise');
var Promise = require('bluebird');
var req1 = 'http://www.bu.edu'; var req2 = 'http://www.cnn.com'; var req3 = 'http://universalhub.com';
function doCalls(message) {
return new Promise(function(resolve, reject) {
resolve(1);
})
.then(function (result) {
rp(req1, function (err, resp) {
});
console.log('step:', result, ' BU ');
return ++result;
})
.then(function (result) {
rp(req2, function (err, resp) {
// console.log('step:', result, ' CNN');
});
console.log('step:', result, ' CNN');
return ++result;
}
)
.then(function (result) {
rp(req3, function (err, resp) {
});
console.log('step:', result, ' UHub');
return ++result;
})
.then(function (result) {
console.log('Ending demo at step ', result);
return;
})
}
doCalls('Starting calls')
.then(function (resolve, reject) {
console.log('Complete');
})
4. Using Promise.resolve to order nested asynchronous calls
/*
Here's the final approach. In this code, each step returns a Promise to the next step, and the
steps run in the expected order, since the promise isn't resolved until
the rp() and its callback are complete. Here we're just manipulating a function variable,
'step', in each step but one can imagine a use case in which each of the calls
would be building up a final result and perhaps storing intermediate data in a db. The
result variable passed into each proceeding then is the result of the rp(), which
would be the HTML page returned by the request.
The advantages of this over the traditional callback method are that it results
in code that's easier to read, and it also simplifies a stepwise process...each step
is very cleanly about whatever that step is intended to do, and then you move
on to the next step.
*/
var rp = require('request-promise');
var Promise = require('bluebird');
var req1 = 'http://www.bu.edu'; var req2 = 'http://www.cnn.com'; var req3 = 'http://universalhub.com';
function doCalls(message) {
var step = 0;
console.log(message);
return new Promise(function(resolve, reject) {
resolve(1);
})
.then(function (result) {
return Promise.resolve(
rp(req1, function (err, resp) {
console.log('step: ', ++step, ' BU ')
})
)
})
.then(function (result) {
return Promise.resolve(
rp(req2, function (err, resp) {
console.log('step: ', ++step, ' CNN');
})
)
}
)
.then(function (result) {
return Promise.resolve(
rp(req3, function (err, resp) {
console.log('step: ', ++step, ' UHub');
})
)
})
.then(function (result) {
console.log('Ending demo ');
return Promise.resolve(step);
})
}
doCalls('Starting calls')
.then(function (steps) {
console.log('Completed in step ', steps);
});
Using Postman to test RESTful APIs
There's a sharp divide in MEAN projects between the back end and the front end. Most use cases involve manipulating model data in some way via either a controller or view-controller, which in MEAN is implemented in Angular. The first work to be done, though, is on the back end, defining and implementing the models and the APIs that sit on top of them.
The typical work flow looks something like:
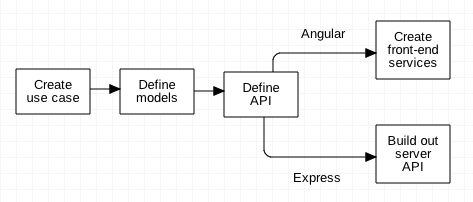
That split is possible because the front end and back end are decoupled; one person can work on the front end and another on the back end once the API has been agreed upon.
There's on tiny problem. How can we test the back end if the front end isn't finished? Let's say you will at some point have a very nice Angular form that lets you create a complex object, and display the results, but it isn't finished, or test requires generating data for multiple views that aren't complete. In these cases we turn to a variety of tools to exercise the back-end API; one of my favorites is Postman, available at getpostman.com.
Postman is essentially a GUI on top of cUrl, a command-line tool that allows us to interact with HTTP services. cUrl isn't too hard to use, but for complex queries it can become a real pain to type everything in the correct order and syntax. Postman takes care of the complexity with a forms-based interface to build, send, and display the results of just about every method you can think of.
Here's Postman's main interface:
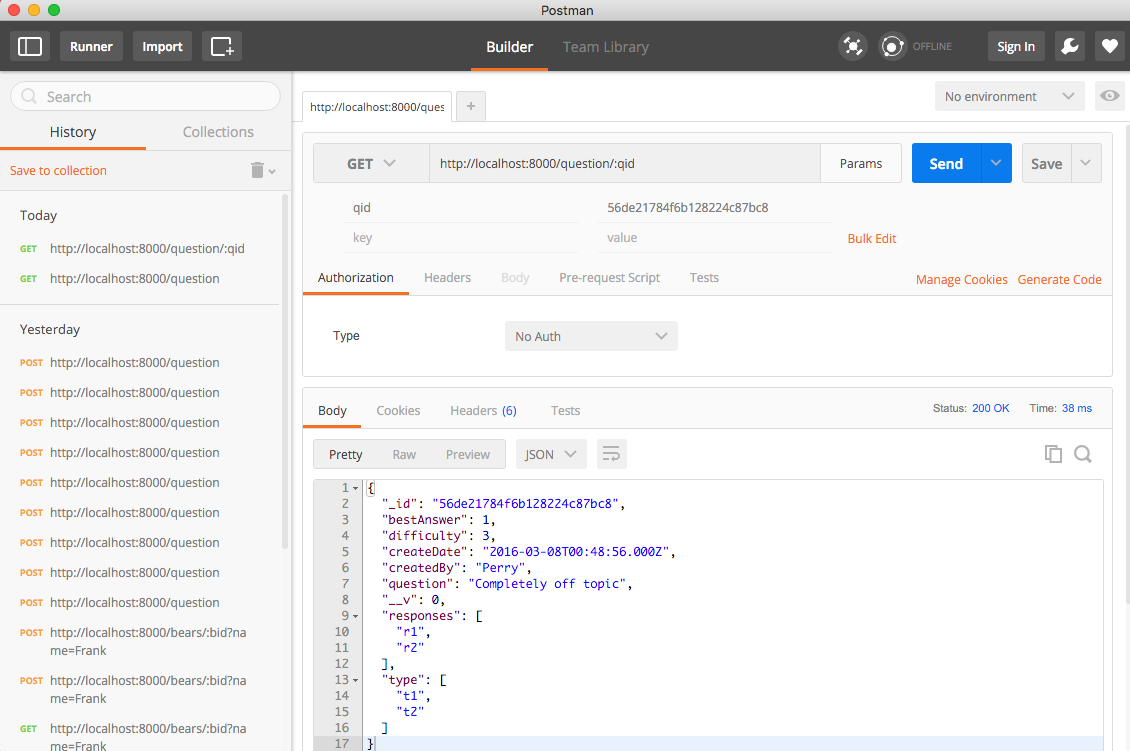
To use it, simply enter the URL of the API you want to test, and enter the appropriate parameters. In the screen shot above I'm doing a GET, passing one parameter, and receiving a JSON object as a result. You can save and edit queries, place queries into tabs, run queries in series, and select an authorization model if you're using one. Also of interest is the 'Generate Code' link which will create code in several languages (Java, Javascript, Node, PHP, Ruby, Python, etc) that you either use directly in your code or include in your test suite.
While Postman and tools like it simplify back-end API development, it's also useful in creating JSON stubs for front-end Angular devs to use for testing until the back end models are fully functional. You can also use it to explore third-party APIs that you might be using...just click Generate Code in the language of your choice to spit out a function to consume the API.
Postman and tools like it solve the chicken-and-egg problem of decoupled development models. It's free, and I think it belongs in every engineer's toolbox.